現場で陥りがちなスケーリングの失敗とその対策を体系的に解説
クラウドの真価は、必要なときに必要な分だけリソースを確保できる「柔軟性」にあります。中でもAWSのオートスケーリングは、正しく設計・運用できれば、コスト最適化と高可用性を両立させる強力な武器となります。
しかし実際には、期待どおりにスケールしなかったり、予期せぬコスト増加を招いたりするケースも少なくありません。オートスケーリングの実装には、緻密な設計と継続的なチューニングが不可欠です。
本記事では、現場で陥りがちな失敗例と対策、安定稼働を支える設計・運用のポイントを解説します。
AWSのAuto Scalingサービスには、Amazon EC2 Auto Scaling、AWS Auto Scaling、Application Auto Scalingの3種類があります。本記事では、最も広く利用されているAmazon EC2 Auto Scaling(以下、EC2 Auto Scaling)を主な対象として解説します。

目次
1.スケーリングとは?
一般論としてのスケーリングの基礎を解説します。
スケーリングが重要な理由
スケーリングとは、システム負荷の増減に応じて処理能力を増減させる仕組みです。
Webサービスには、時間帯、季節、キャンペーンなどによる「アクセスピーク」が必ず存在します。ここでリソースが不足すれば、レスポンス遅延やシステムダウンによる機会損失を招きます。
一方、常にピーク時に合わせる過剰なリソース確保は、低負荷時の無駄なコストを発生させます。スケーリングは、この「性能とコストのトレードオフ」を解決するための仕組みです。
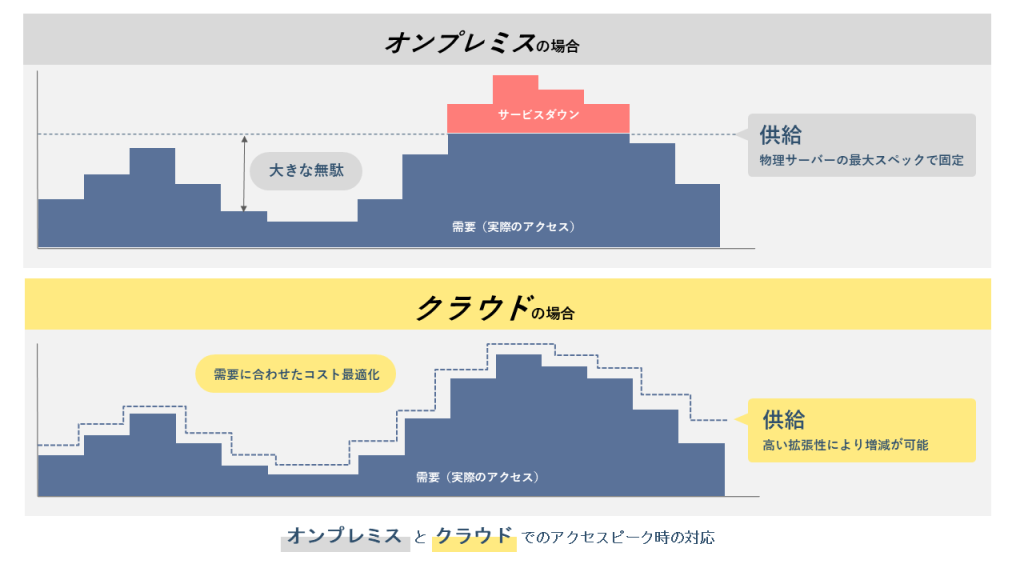
オンプレミスとクラウドでのアクセスピークへの対応
オンプレミスでは将来のピークを予測し、事前に物理サーバーを調達しなければなりません。調達には長いリードタイムがかかり、需要が予測ピークを超えてサービスダウンしたり、過剰調達によるコストの無駄が常態化したりするおそれがあります。
対してAWSをはじめとするクラウドでは、インスタンスを数分以内に起動・削除できます。この高い拡張性を活かし、アクセスピークへの対応とコストの最適化を同時に実現できる点が、オンプレミスとの本質的な違いです。
ただし、AWSアカウントごとにサービスの上限があるため、設計上の制約を事前に理解しておくことが重要です。
2.AWSで実現できるスケーリングの仕組み
AWSにおけるスケーリングの具体的な手法を解説します。
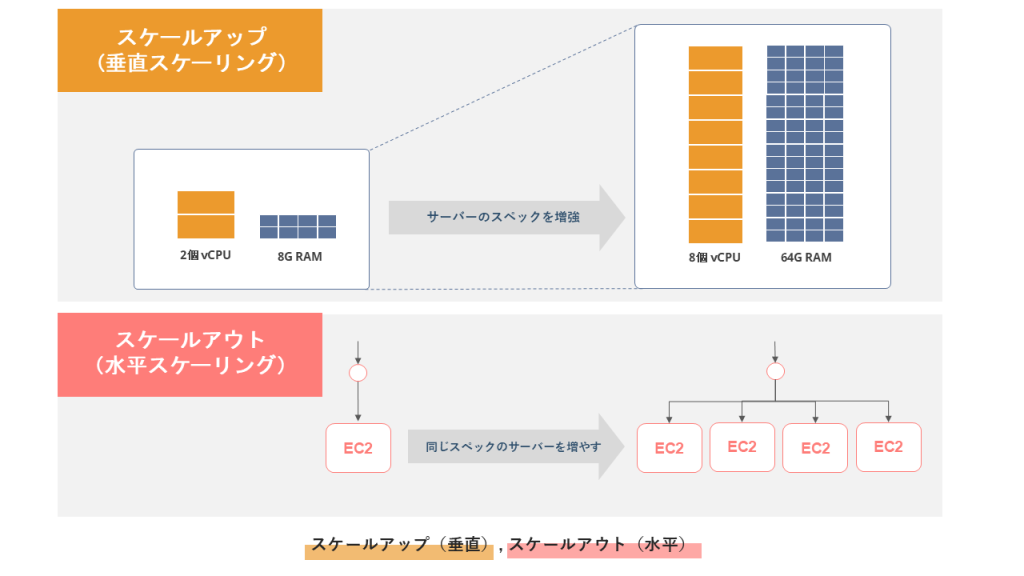
スケールアップ・スケールアウト
スケーリングには、スペックの増減「垂直スケーリング(スケールアップ/ダウン)」と、台数の増減「水平スケーリング(スケールアウト/イン)」の2種類があります。
垂直スケーリングは、インスタンスタイプの変更などにより、リソース単体の性能を増減させる手法です。書き込み負荷が高いデータベースなど、分散が困難な箇所に適していますが、通常は変更時にダウンタイムを伴い、物理的な性能上限が存在します。
水平スケーリングは、EC2 Auto Scalingのようにインスタンス数を増減させる手法です。Webサーバーやアプリケーションサーバーなど、ステートレスなWeb層に最適で、可用性を維持したまま性能を拡張できるメリットがあります。
スケーリングを支えるAWSの仕組み
EC2 Auto Scaling
Auto Scalingグループと呼ばれるEC2インスタンスの集合を定義し、最小数、最大数、希望数を指定することで、グループ内のインスタンス数を自動で管理・作成する仕組みです。
EC2 Auto Scaling自体の利用は無料ですが、起動したEC2インスタンスやEBSボリューム、スケーリング精度を向上させるためのCloudWatch詳細モニタリング有効化など、実際に使用したリソースに対して課金が発生する点に注意が必要です。
主なスケーリング手法は以下のとおりです。
| スケーリング方法 | 概要 |
| 動的 | CPU使用率やリクエスト数などのメトリクスに応じて増減。以下のポリシーから用途に応じて選択。 ・ターゲット追跡: 「CPU使用率60%維持」など、目標値へ自動追従する。最も一般的で設定が容易な標準手法。 ・ステップ: メトリクスの値の範囲(ステップ)ごとに増減台数を段階的に変えられる。「CPU 70〜80%なら2台、80%超なら5台」といった制御が可能。 |
| スケジュール | 指定日時にインスタンス数を増減。始業時のログイン集中や夜間バッチなど、発生タイミングと負荷量が予測できる場面で有効。 |
| 予測 | 機械学習で過去の履歴を分析し、将来の需要を予測して自動増強。曜日・週・季節によって負荷量が変動するような場合に有効。 |
Elastic Load Balancing(ELB)
EC2 Auto Scalingと連携してスケーリングを完結させるために不可欠な要素です。インスタンスが増えても、トラフィックを自動分配する仕組みがなければスケーリングの効果は発揮されません。
ELBはユーザーに対して単一の入口を提供します。背後でインスタンスが何台増減しても、ユーザーはその変化を意識しなくて済みます。主な役割は、各インスタンスへのリクエスト分配、ヘルスチェック、スケールイン時の通信断防止の3点です。
関連記事:AWSのロードバランサーとは?種類や用途、料金体系を詳しく解説
スケーリングの応用用途
負荷対応以外に、リソースのライフサイクル管理としても活用可能です。
インスタンスリフレッシュ(デプロイへの活用)
AMIや起動テンプレートの更新時、EC2 Auto Scalingのインスタンス更新機能を用いて、ローリング方式で新旧のインスタンスを順次置換できます。段階的に置換して影響を確認しながら更新できるため、安全な更新運用に活用できます。
自己修復
「希望する容量=1、最小=1、最大=1」に固定すれば、障害停止時に自動で新しいインスタンスを起動して復旧させる「自己修復」の仕組みとして機能します。冗長化が難しいレガシーシステムにも応用できます。
3.AWSスケーリングでのよくある失敗
スケーリングで陥りがちな失敗と対策を解説します。
ライフサイクル制御の不備
スラッシング(チャタリング)
スケールアウトとスケールインの閾値が近すぎたり、クールダウン期間が短すぎたりして、インスタンスの「起動」と「削除」が短時間に繰り返される現象です。
「CPU 70%で増、40%で減」といった余裕を持たせた閾値設定や、インスタンスの起動完了からリクエスト処理開始までの時間を正確に把握し、その間はスケーリングアクションを抑制するクールダウン期間の最適化が必要です。
スケーリングが間に合わない
急激なスパイクアクセスが発生した際、EC2 Auto Scalingがスケールアウトを完了するまでの間に、既存サーバーが過負荷でダウンしてしまうことがあります。CloudWatchの基本モニタリングがデフォルト5分間隔であるために状況把握に遅れが生じることや、EC2の起動・初期化に時間がかかりすぎることが主な原因です。加えて、CloudWatchアラームの評価設定(評価期間など)や、インスタンスウォームアップ設定が長すぎることも、遅れの原因となります。
対策として、インスタンスの起動完了とほぼ同時にサービスを開始できるよう、セキュリティパッチ・ミドルウェア・アプリケーションの設定をすべて含めた、いわゆる「Golden AMI」の使用や、CloudWatchの詳細モニタリング(1分間隔)を有効化して早期検知することが有効です。
また、「Warm Pools」を活用し、インスタンスをあらかじめプールしておくと、起動・初期化に時間がかかるワークロードでもスケールアウトまでの待ち時間を短縮しやすくなります。
ゾンビインスタンスによるコスト増加
プロセスのハングアップや応答不能といった不健全な状態にもかかわらず、ヘルスチェックの設定不備によって異常が検知されず、自動終了されないまま残存し続けて不要な課金が発生する状態を「ゾンビインスタンス」と呼びます。
防止策として、ELBとEC2 Auto Scalingのヘルスチェック連携、およびスケールイン保護を適切に設計してください。また、万が一の異常増殖に備え、予算と依存リソースの限界値に基づいた最大容量を厳格に設定し、リソースの増加範囲を統制します。
アーキテクチャの不整合
セッションの断絶
スケールイン時にEC2インスタンスが削除された際、そのサーバー内にセッション情報を保存しているステートフルな設計だと、接続中のユーザーが突然ログアウトされるなどの問題が生じます。
ElastiCache(Redis)などでセッションを外部管理する「ステートレス化」が、水平スケーリングを機能させるための大前提です。あわせて、ELBの「登録解除の遅延」を適切に設定し、既存処理の完了を待ってからインスタンスを切り離す仕組みを組み込みます。
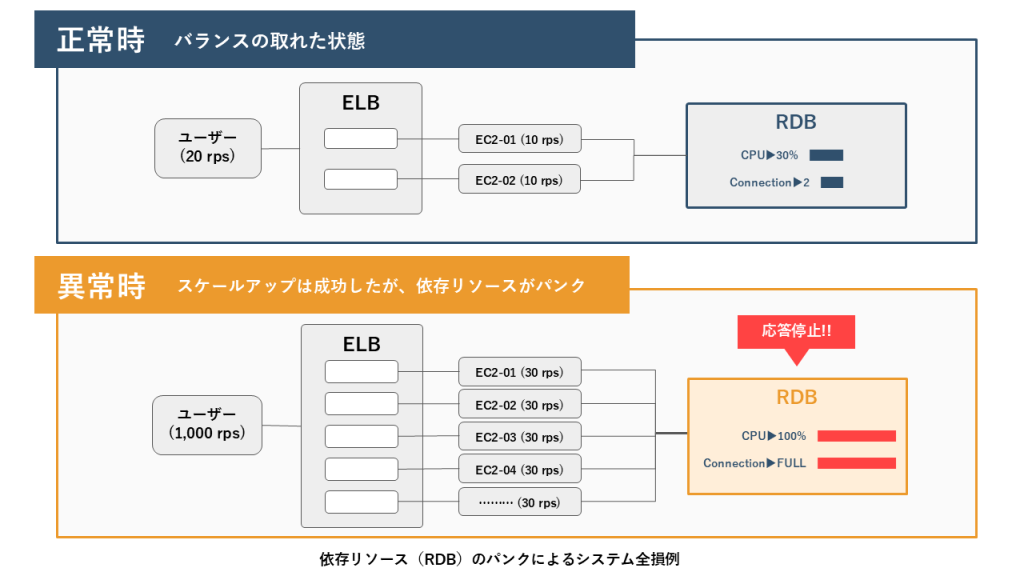
依存リソースのパンク
EC2のスケーリングに成功しても、その先にあるRDSが最大コネクション数に達すれば、システム全体が停止してしまいます。EC2インスタンスの最大台数は、依存リソースの限界から逆算するという視点が必要です。
全レイヤーを俯瞰した負荷試験を行い、スケーリング発生時の依存リソースの振る舞いを事前に確認することが不可欠です。
ヘルスチェックのミス
EC2のデフォルトヘルスチェックは、OSが起動しているかのみを確認するため、ApacheやNginxがクラッシュしていても「正常」と誤認します。ELBのヘルスチェック(HTTP 200 OKが返るかを確認)とEC2 Auto Scalingを連携させることで、アプリケーション層の異常を検知し、異常インスタンスの自動排除・補充が正常に機能します。
プラットフォームの制限
AWSアカウントやリージョンには、起動できるEC2インスタンス数などの制限が存在します。設計が完璧でも、この上限に達すればスケールアウトは失敗します。
あらかじめ現在の制限値を確認し、予想最大負荷に対して余裕があるかを検証してください。必要であれば、制限緩和申請を事前に提出しておくことが重要です。
4.AWSで作るスケーラブルな構成の設計・運用ポイント
スケーリングの設計と運用のポイント、コスト最適化の方法を解説します。
EC2 Auto Scalingを例とした設計手順とポイント
スケーリング設計は、以下の手順で進めることが望ましいです。
1)ピーク負荷の定量化
ビジネス予測と過去のトレンドに基づき、ピーク時の最大同時接続数や秒間リクエスト数を数値化します。あわせて、1リクエストあたりの消費リソース(CPU・メモリ)も計測しておきましょう。
2)インスタンスあたりの限界値特定
単一のインスタンスに対して負荷試験ツール(JMeterやLocustなど)をかけ、ボトルネック(CPU・メモリ・ネットワーク帯域など)を特定します。その限界値の80%程度を「運用上の上限」と定義するのが一般的です。
3)依存リソースの確認と逆算
インスタンス最大数稼働時のRDS接続数やIPアドレス数の余力を確認します。「EC2インスタンスは増やせても、他リソースはそうはいかない」という前提で、依存リソースの限界からインスタンスの最大数を逆算します。
4)スケーリングポリシー策定
メトリクスの選定(CPU使用率かリクエスト数か)、ターゲット追跡ポリシーの設定(常にCPU 60%を維持など)、あるいはスパイクへの対応のためステップスケーリング(CPU 80%超で一気に5台増やすなど)など、具体的なスケーリングポリシーを検討します。
5)起動速度の短縮
必要な設定をすべて完了させた「Golden AMI」の採用や、「Warm Pools」による待機インスタンスの確保により、起動時間の最小化を図ります。
稼働後の監視・測定とチューニング
稼働後は、以下の3大指標を継続的に計測することが重要です。なお、設定変更後は必ず変更前後のメトリクスを比較し、改善効果を定量的に確認してください。
- スループットとレイテンシ: ELBのCloudWatchメトリクスを監視します。EC2インスタンスが増えてもレイテンシが改善しない場合、DBやネットワークなど別の箇所にボトルネックがあると判断できます。その場合は、EC2 Auto Scalingのポリシー変更よりも先に、依存リソース側の限界を取り除くことが重要です。
- スケーリングの挙動: EC2 Auto Scalingグループのメトリクスで稼働・終了数を監視します。スラッシングを検知した場合は、閾値の不感帯の見直しと、クールダウン期間の延長を行います。
- コスト効率: Cost ExplorerとCompute Optimizerを活用します。特に後者は、機械学習により最適なインスタンスタイプを提案するため、過剰投資の是正に有効です。
コスト最適化の方法
以下の手順でEC2 Auto Scaling環境のコスト最適化を行えます。
1)現状を可視化
14日間程度の稼働後にCompute Optimizerを確認し、オーバープロビジョニングとインスタンスタイプの変更候補を特定します。また、CPU使用率が常に10%以下のインスタンスが存在する場合は、最小台数の引き下げを検討してください。
2)インスタンスのハイブリッド化
すべてオンデマンドでEC2 Auto Scalingグループを構成するのはコスト効率の低い選択です。ベースはリザーブドインスタンスまたはSavings Plansを適用し、増分はスポットインスタンスを優先的に使用する混合インスタンスポリシーへ切り替えることで、大幅なコスト削減が可能となります。
ただし、スポットインスタンスにはAWSの都合により突然回収(中断)されるリスクがあります。そのため、複数の類似インスタンスサイズを許可して在庫切れ・回収時の代替調達を容易にしておくこと、中断されても処理を再開できるステートレスな設計を前提とすることの2点が必須条件です。
関連記事:
AWSリザーブドインスタンスとは?種類やメリット、料金体系を解説
AWSのSavings Plans(SP)を徹底解説|RIとの違い・メリット・ユースケースまで紹介
3)周辺コストの見直し
隠れたコストとして見落としやすいものに、以下の項目があります。
- EBSボリューム残存: インスタンス削除後にEBSが残存しないよう「DeleteOnTermination」を有効化します。
- CloudWatch詳細モニタリング: インスタンス数に比例して課金が増えるため、不要なメトリクス収集は停止し、必要な指標に絞り込みます。
関連記事:
AWSのコストの仕組みは?見積もり方法や最適化するポイントを解説
AWSコストを最適化する実践プロセス|設計原則とベストプラクティスをもとに解説
5.まとめ
オートスケーリングの本質は、需要変動に応じて確実にリソースを伸縮させながら、無駄なコストを抑える最適化にあります。その実現には適切な設計と継続的なチューニングが不可欠ですが、高度な運用体制が求められるため、自社のみで維持するのは容易ではありません。
ハートビーツではアクセスピークの激しいサービスをご支援してきた実績を元に、事前の負荷テストやスケーリングの設定から伴走します。[プロ野球の配信システムで数万人の同時アクセスを支える支援事例]もございますので、お気軽にご相談ください。
#サーバー監視一次対応サービス
#フルマネージドサービス
#AWS 請求代行サービス







