監視設計の考え方から体制づくりまで実務視点で整理
AWSの利用が広がるなかで、「システムの異常をどこまで監視すべきかわからない」「監視設定はしているものの、重要なアラートを見極められない」といった課題を抱える企業は少なくありません。
クラウド環境ではリソース構成や負荷状況が変化しやすく、オンプレミスと同じ考え方のままでは安定運用が難しくなることがあります。こうした課題を解決するために重要なのが、AWS監視の設計と運用です。
本記事では、AWS監視の基本的な考え方から、監視の種類、よくある失敗、監視設計と体制づくりのポイントまでわかりやすく解説します。
関連コンテンツ:AWSインフラ運用の棚卸しチェックリスト(無料)

目次
1. AWS監視はなぜ重要?クラウド運用で監視が欠かせない理由
AWS監視とは、AWS上で稼働するシステムやサービスの状態を継続的に把握し、異常を早期に検知して対応につなげるための取り組みです。
この記事で扱う「監視」は、主に可用性(死活)の確認、性能(メトリクス)の把握、ログによる原因特定、通知や一次対応につなげるための運用を指します。AWSにおけるセキュリティ監視や脅威検知については、以下の記事をご覧ください。
関連記事:AWS環境に必要なセキュリティ対策とは?考え方から具体的なサービスまで
AWS監視の必要性
AWS監視が必要とされるのは、システムの異常や性能低下が発生した際、適切な監視設計がなされていなければ異常に気づけないためです。
特にAWSのようなクラウド環境では、リソースの増減や設定変更が頻繁に行われるため、想定外の挙動や設定ミスが発生しやすく、監視の重要性が高まります。また、サービスが継続的に稼働するなかで障害や負荷増大が発生した場合、業務停止や機会損失、ユーザー体験の低下といったビジネス影響を及ぼすおそれがあります。
異常を早期に検知できれば、ビジネスに影響が出る手前で食い止める、あるいは影響が出た場合でも迅速な復旧につなげることが可能です。
オンプレミス環境との違い
オンプレミス環境では、物理サーバーやネットワーク機器を自社で保有します。構成の変化が少ないため、監視対象をあらかじめ定めやすく、物理機器の状態も含めて把握しやすい環境です。
一方、AWSをはじめとするクラウド環境では、マネージドサービスの利用が多くなります。利用者が直接確認するのは物理基盤ではなく、論理的なリソースやサービスの状態が中心です。
また、オートスケーリングや構成変更により、監視対象が動的に変化することも少なくありません。そのため、従来の固定的な監視の考え方では対象漏れが起こりやすく、メトリクスやログをもとに継続的に状態を把握できるよう、監視を設計することが重要です。
2. AWS監視の基本|監視の種類と主要なサービス
AWS環境における監視の主な種類と、それぞれの監視を支える主要なAWSサービスを解説します。
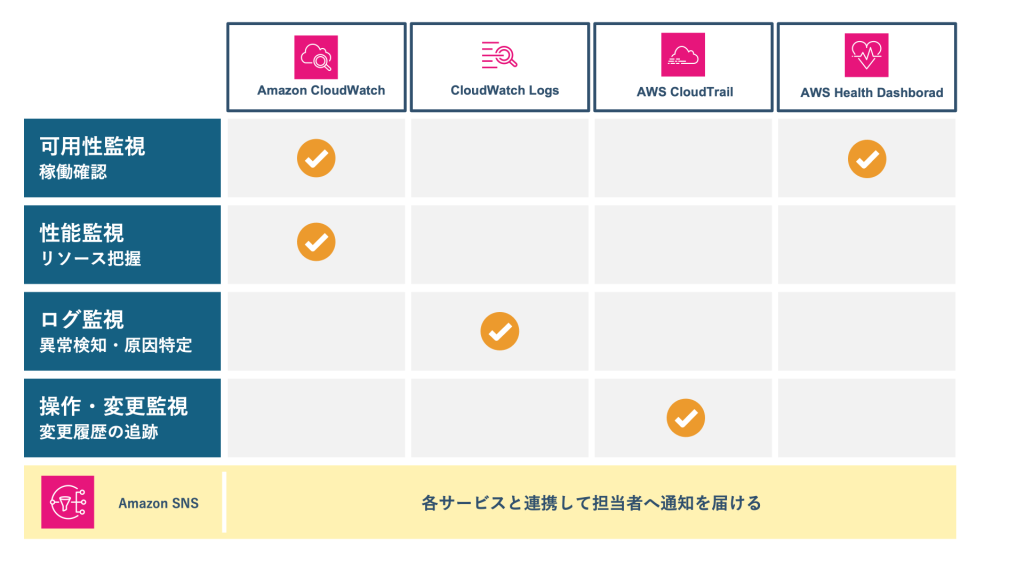
AWS監視の主な種類
実運用で特に重要となる4つの観点に分けて整理します。
可用性監視
システムやサービスが正常に稼働しているかを確認するための監視です。たとえば、EC2やRDSが停止していないか、アプリケーションが応答しているか、AWSサービス側で障害やメンテナンスが発生していないかなどを把握します。サービス停止や業務影響を早期に検知するうえで基本となる監視です。
性能監視
システムの処理性能やリソース使用状況を把握するための監視です。CPU使用率、メモリ使用状況、ディスク容量、レスポンスタイム、ネットワーク負荷などを継続的に確認することで、性能低下やリソース不足の兆候を捉えやすくなります。障害の予防やキャパシティ調整の判断にもつながります。
なお、EC2のメモリやディスクなどのOS内部のメトリクスは、標準の監視項目として自動取得されないため、CloudWatch Agentなどを用いた収集設計が必要です。
ログ監視
システムやアプリケーションが出力するログを収集・分析し、異常の検知や原因特定に役立てる監視です。エラーログやアクセスログを確認することで、表面的なアラートだけでは見えない問題の詳細を把握しやすくなります。障害対応の精度を高めるためにも重要です。
なお、OSやアプリケーションのログは自動的に集約されないため、出力先や保管方法、外部への転送設定を含めた収集設計が必要です。
操作・変更監視
AWS環境で誰が・いつ・何を変更したかを把握するための監視です。設定変更やAPI実行履歴を確認できれば、障害発生時に直前の変更内容を追いやすくなります。意図しない設定変更の早期発見や、原因調査の迅速化に有効です。
AWSの主要な監視サービス
上記の監視をAWS上で実現する際は、用途に応じて複数のサービスを使い分けることが一般的です。ここでは、AWSが提供する主要な監視サービスを紹介します。
Amazon CloudWatch
AWS監視の中心となる代表的なサービスです。メトリクスの収集、アラーム設定、ダッシュボード表示などが可能であり、可用性監視や性能監視の中核を担います。
Amazon CloudWatch Logs
アプリケーションやOS、各種AWSサービスが出力するログを収集・管理するサービスです。ログの可視化や検索、異常の検知に活用でき、原因特定やログ監視に役立ちます。
AWS CloudTrail
AWSアカウント内で実行されたAPI操作や設定変更の履歴を記録するサービスです。操作・変更監視に活用でき、障害の原因調査や変更履歴の確認に重宝します。
AWS Health Dashboard
利用しているAWSサービスの障害情報やメンテナンス予定を確認できるサービスです。自社の設定やシステムだけでなく、AWSサービス側の問題を把握するためにも重要です。
Amazon SNS
監視そのものを行うサービスではありませんが、CloudWatchアラームなどと連携して通知を送る役割を担います。異常を検知して終わりにするのではなく、担当者への通知や初動対応につなげるために重要なサービスです。
3. AWS監視でよくある失敗
ここでは、AWS監視で起こりやすい代表的な失敗を取り上げます。
監視対象が不足しており異常の兆候を見逃してしまう
監視設定を行っていても、対象が一部のリソースや基本的な死活監視に限られていると、異常の兆候を十分に捉えられないことがあります。たとえば、EC2の起動状態だけを監視していても、CPU使用率の急上昇やディスク容量の逼迫、アプリケーションのエラー増加には気づけないケースがあるため注意が必要です。
AWSでは構成や利用サービスが変化しやすいため、必要な監視対象を整理しないまま運用すると、重要な変化を見逃すリスクが高まります。
アラート設計が不十分で重要な異常に気づけない
アラート設計の不備は、重要な異常を見逃す原因になります。たとえば、しきい値が適切でなかったり、通知が多すぎたりすると、本当に確認すべきアラートが埋もれてしまいかねません。
逆に通知条件が粗すぎると、重大な異常が起こっても担当者が即座に察知できないことがあります。こうした状態では、監視を行っていても実運用に活かせず、異常検知から対応までの初動が遅れやすくなります。
ログを取得していても原因特定や対応に活かせていない
ログを保存しているだけで、実際の障害対応に活用できていないケースも散見されます。障害発生時に必要なログをすぐに確認できなかったり、どこに何のログがあるのかが不明確だったりすると、原因特定に時間がかかります。
エラーログやアクセスログが取得されていても、調査しやすい形で整理されていなければ、障害時の判断材料として十分に機能しません。その結果、復旧までの時間が長引き、根本的な再発防止策の立案も難しくなります。
異常検知後の対応体制が決まっておらず初動が遅れる
異常を検知できても、その後の対応体制が未整備であるために、運用が止まってしまうことがあります。たとえば、誰が通知を受けるのか、夜間や休日は誰が確認するのか、どこまでを一次対応の範囲とするのかが曖昧だと、アラートが発生しても迅速に動けません。
特に少人数体制では、平日日中は対応できても、それ以外の時間帯の対応が手薄になりがちです。こうした状態では、監視設定自体が存在していても、組織としての安定運用にはつながりません。
4. AWS監視設計の考え方|実運用で機能する監視設計のポイント
ここでは、AWS監視設計を検討するうえで押さえておきたい基本的なポイントを解説します。
監視は後付けではなく設計段階から組み込む
AWS監視は、システム構築後に不足分を追加するのではなく、設計段階から組み込むことが重要です。監視を後付けにすると、必要なメトリクスやログを取得できなかったり、通知条件や運用フローとの整合が取れなかったりするおそれがあります。
特にAWSでは、EC2、RDS、Lambda、コンテナ、マネージドサービスなど構成要素が多岐にわたり、あとから監視を追加しようとすると抜け漏れが起こりがちです。安定運用を前提とするなら、どのサービスを使い、どの異常を検知し、どこまで対応するのかを、システム設計とあわせて考えておく必要があります。
重要なメトリクスに絞って監視対象を設計する
監視においては、できるだけ多くのデータを取得すればよいわけではありません。監視対象を広げすぎると、確認すべき情報が増えすぎて運用負荷が上がり、かえって重要な異常を見落としやすくなります。
AWSのベストプラクティスでも、重要なメトリクスに焦点を当てる考え方が示されています。たとえば、EC2であればCPU使用率やステータスチェック、RDSであれば接続数やストレージ容量、アプリケーションであればレスポンスタイムやエラー率など、ビジネス影響の大きい指標を優先して設計することが重要です。
まずは「何が起こると困るのか」を明確にし、その兆候を捉えられる監視項目から整備するとよいでしょう。
ログ・メトリクス・トレースを組み合わせた多層監視を行う
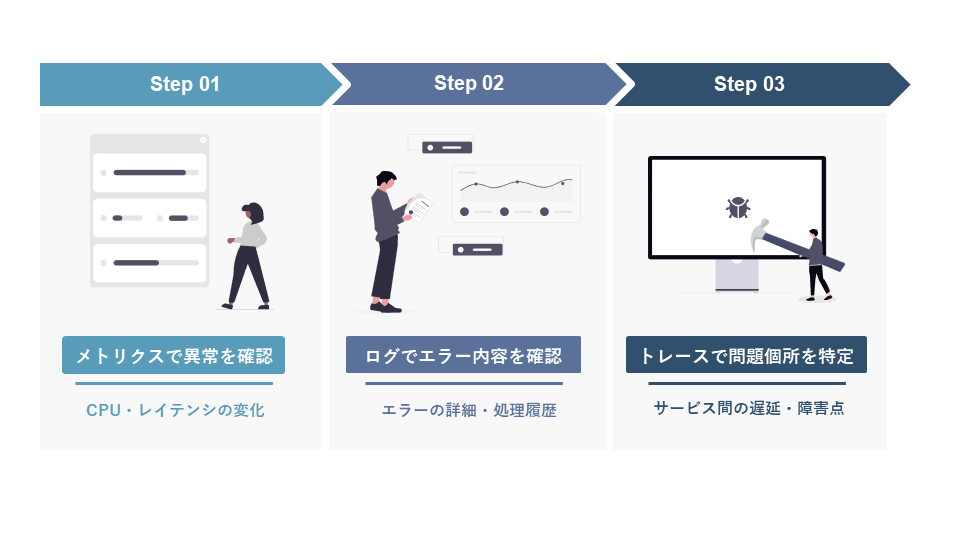
監視においては、単一の視点ではなく、複数のデータを組み合わせて状況を捉えることが重要です。
メトリクスはCPU使用率やレイテンシなどの定量的な変化を捉えるのに適しており、ログはエラー内容や処理の詳細確認に役立ちます。さらに、複数サービスをまたぐシステムでは、どこで遅延や障害が起こっているのかを追うためにトレースも有効です。
AWSでも、ログ・メトリクス・トレースを組み合わせてシステムの状態を把握する考え方が重視されています。たとえば、CloudWatch(メトリクス)で異常を検知し、CloudWatch Logs(ログ)で原因候補を絞り込み、AWS X-Ray(トレース)で遅延の発生箇所や呼び出し経路を特定する、といった形で多層的に切り分けるアプローチをとることで、原因の早期特定と迅速な復旧が可能になります。
アラートは運用を前提に設計する
監視設計では、異常を検知する条件だけでなく、どのように通知し、どう扱うかまでを考えなければなりません。しきい値が厳しすぎればアラートが多発し、運用担当者が重要な通知を見逃す原因となります。逆に条件が緩すぎれば、重大な異常の発見が遅れるリスクが生じます。
AWSのベストプラクティスでも、アラート疲れを避けることの重要性が示されています。アラートは単に発報させるのではなく、重要度に応じた優先順位付け、通知先の整理、夜間休日の扱いまで含めて設計することが重要です。
「検知できること」と「現実的に対応できること」は別物であるため、実際の運用体制と整合性の取れたアラート設計を心がけましょう。
検知後の対応フローまで含めて監視設計を行う
AWS監視において、異常の検知はあくまで手段であり、ゴールではありません。重要なのは、検知後に適切な初動対応へつなげられることです。
そのため、誰が通知を受けるのか、一次対応はどこまで行うのか、どの時点でエスカレーションするのかといった対応フローまで含めて監視設計を考える必要があります。
少人数体制や兼任体制では、通知だけが飛んで実際には誰もすぐに動けない状況が起こりやすいでしょう。こうした事態を避けるには、監視設定とあわせて、連絡経路、対応手順、判断基準を明確にしておくことが重要です。
監視が実運用で機能するかどうかは、設定の巧拙だけでなく、検知後の動きが整理されているかに大きく左右されます。
継続的に改善する前提で運用する
AWS監視は、一度設定して終わりではありません。クラウド環境では、利用サービスの追加、構成変更、トラフィックの増減などによって、適切な監視対象やしきい値も変化していきます。
運用を続けるなかでは「不要なアラートが多い」「確認したいログが足りない」「通知は届くが対応判断に迷う」といった課題が見えてきます。こうした運用上の気づきを反映しながら、監視対象やアラート条件、対応フローを見直していくことが重要です。
AWS監視には、初期設定の完成度だけでなく、改善を前提に育てていく視点が求められます。
5. AWS監視体制の考え方|ユースケース別の監視体制例
AWS監視に必要な体制は、すべてのシステムで一律ではありません。ここでは、代表的なユースケースごとに監視体制の考え方を整理します。
小規模サービス・検証環境の監視体制
小規模な社内利用サービスや検証環境では、24時間365日の監視体制までは求められないケースがほとんどです。この場合は、営業時間内を中心に基本的な可用性監視や性能監視を行い、異常発生時は兼任担当者が対応する体制が現実的でしょう。
ただし、簡易的な監視で十分な環境であっても、最低限の通知設計やログ確認の流れを決めておかないと、異常の発見が遅れるおそれがあります。規模が小さい環境ほど、監視を省くのではなく、必要最小限の項目に絞って設計することが重要です。
業務システム・社内基幹システムの監視体制
業務システムや社内基幹システムでは、障害が業務停止や生産性低下に直結するため、重要アラートを中心に監視体制を整える必要があります。たとえば、業務時間中は即時に確認し、夜間休日は重要度の高いアラートのみを通知するなど、ビジネスへの影響度を踏まえた運用が現実的です。
一方で、情シスやインフラ担当が他業務と兼任している場合、通知を受け取れても初動が遅れることがあります。そのため、どの障害を優先的に対応するのか、誰が判断するのかを事前に明確化しておくことが不可欠です。
高可用性が求められるサービスの監視体制
顧客向けサービスや、停止による影響が大きいシステムでは、24時間365日体制で監視し、異常発生時に即時対応できる体制が求められます。こうした環境では、可用性監視や性能監視だけでなく、ログ監視や復旧判断を含めた運用体制の整備が必要です。
しかし、専任の担当者を配置し、24時間体制を自社リソースのみで維持し続けることは容易ではありません。特に少人数体制では、夜間休日の対応が手薄になりやすく、監視設定があっても実運用で機能しないケースもあるでしょう。
そのため、求められる可用性に応じて、外部の監視・運用支援サービスを活用することも有力な選択肢となります。
6. AWS監視についてよくある質問
最後に、AWS監視に関してよくある質問と回答をまとめました。
Q. AWS環境はどこまで監視すれば十分と言えますか?
A.AWS監視では「すべてを監視すること」が正解ではありません。重要なのは、自社のサービスにおいて影響が大きい指標を定義し、それに基づいて監視対象を設計することです。過剰な監視はアラートの増加や運用負荷の増大を招くため、ビジネス影響を基準に優先順位をつけることが重要です。
Q. 監視設計と運用はどこまで自社で対応すべきですか?
A.自社で対応すべき領域は、何を重要な異常とみなすのか、どのレベルの障害まで許容できるのかといった運用方針の策定です。これらは自社の業務特性やサービス影響を踏まえないと判断しにくいため、内製で考える必要があります。
一方で、監視設定の実装や24時間365日の監視、一次対応、アラートの監視運用などは、自社の体制やリソースに応じて外部委託を活用するのが有効です。特に少人数体制で夜間休日の対応が難しい場合や、専門的な知見を継続的に確保しにくい場合は、外部サービスを活用することで、安定運用を実現しやすくなるでしょう。
まとめ
AWS監視は、AWS上のシステムやサービスの状態を継続的に把握し、異常を早期に検知して対応につなげるための取り組みです。
監視では、可用性や性能、ログなどを適切に把握し、異常検知にとどまらず、原因特定や復旧判断までをスムーズに行える状態を整えることが重要です。そのため、AWS監視はツール設定だけで完結するものではなく、監視項目やアラート、対応フローまでを含めて設計・運用する必要があります。
ハートビーツでは、24時間365日の有人監視と一次対応を行う「サーバー監視一次対応サービス」に加え、運用全体を支援する「フルマネージドサービス」も提供しています。AWS監視を実運用で機能する体制として定着させたい場合は、ぜひハートビーツへご相談ください。








