〜AWSの主要サービスを活用した高可用性のベストプラクティスも紹介〜
AWSの導入や活用を検討する際、多くの企業が直面するのが「可用性をどう確保するか」という課題です。可用性が損なわれてサービスが止まれば、ユーザー体験や事業継続に直結します。障害発生時でも影響を最小限に抑え、短時間で復旧できる仕組みづくりが欠かせません。
高可用性を実現するには、冗長化や耐久性の確保といった設計段階での工夫に加え、運用フェーズでの監視や改善サイクルも重要です。本記事では、AWSにおける可用性の基本から、主要サービスを活用したベストプラクティス、設計時に考慮すべきポイントまでを解説します。現行システムの可用性に不安を抱えている方は、見直しのきっかけとして活用してください。

目次
1. AWSにおける可用性の重要性
AWSにおける可用性は、クラウド基盤が持つ冗長性や自動化機能を前提としつつ、利用者自身の設計と運用によっても左右されます。そのため、障害を想定した設計と復旧を見据えた運用体制が必要です。
そもそも可用性とは
可用性とは、システムを利用可能な状態に維持できる度合いを示す概念です。サービスが停止すれば利用者の信頼を損ない、直接的な損失につながるため、最優先で考慮すべき設計要件といえます。
また、可用性は、SLA(Service Level Agreement:サービス品質保証)とも密接に関連しています。SLAはサービス提供者が利用者に対して保証する稼働時間や品質を明文化したものであり、可用性はその中で主要な指標として定義されます。
つまり可用性は、技術的な安定性を示すだけではなく、契約やサービス水準を判断する基準としても扱われる重要な概念です。
AWSにおける障害と可用性
クラウドは高い信頼性を持つ基盤を提供していますが、それだけで障害がなくなるわけではありません。停電や自然災害、ハードウェアの故障、ソフトウェアの不具合など、多様な要因でシステム停止は発生する可能性があります。
したがって、クラウド利用においても「障害を前提とした設計」が欠かせず、AWSでも高可用性を確保するためのさまざまなサービスを提供しています。
2. AWSの可用性設計の基本
AWS環境の可用性を高めるうえでの基本について解説します。
冗長化
冗長化とは、万一の障害に備えてシステムを複数の拠点やリソースに分散させることです。単一のサーバーやデータセンターに依存すれば、その要素が停止したときに全体も止まってしまいます。
AWSにおいては、リソースを複数のリージョン(地理的に独立した拠点)やアベイラビリティゾーン(AZ:1つのリージョン内にある独立したデータセンター群)に分散して配置することで、単一のデータセンターや地域に障害が生じても、別の拠点で業務を継続可能です。この冗長構成により、システム全体の信頼性と可用性を確保できます。
また、一部のサービスは標準でマルチAZ冗長化を備えています。マルチAZ冗長化とは、同じデータを複数のAZに分散して保持することで、1つのAZが障害で停止してもほかのAZから処理を継続できる仕組みです。
例えば、Amazon S3やAuroraなどは、利用者が特別な設定を行わなくても複数拠点にデータを保持できる仕組みを持ちます。こうした分散設計によって、障害が発生してもシステムを継続させる体制を整えることが可能です。
耐久性
耐久性とは、保存したデータが壊れたり失われたりしにくい度合いを指します。システムが稼働していても、基幹データが破損すれば業務は継続できないため、可用性を支える重要な要素です。
AWSのストレージサービスは内部的に複数コピーを保持し、ディスクや機器の障害からデータを守る仕組みを備えています。さらに、バックアップやスナップショット、バージョニング(S3でファイルの世代管理を行い、誤削除や上書きから復元できる仕組み)を活用すれば、人為的な削除やアプリケーション不具合にも備えることが可能です。
重要なデータほど、より耐久性の高い仕組みに置くことが設計上の基本となります。
負荷分散
負荷分散とは、ユーザーからのリクエストや処理を複数のリソースに分散する仕組みです。アクセスが一部のサーバーに集中すると、遅延や停止の原因となりかねません。複数のサーバーやコンポーネントに負荷を均等化すれば、ピーク時でも安定したサービス提供を維持できます。
AWSにはアプリケーション層やネットワーク層で動作するロードバランサーサービスが用意されており、オートスケーリングと組み合わせることで、トラフィックの増減に応じて柔軟にリソースを調整できます。この仕組みによって、障害を防ぐだけではなくリソースの最適利用も実現可能です。
関連記事:AWSのロードバランサーとは?種類や用途、料金体系を詳しく解説
保守性・運用性
保守性とは、障害が発生した際にいかに短時間で復旧できるか、また将来的な修正や改善をいかに容易に行えるかを示す考え方です。AWS環境では、監視によって異常を早期に検知し、自動通知や自動復旧の仕組みを整えることが重要です。
また、定期的なバックアップやスナップショットを取得しておけば、万一の障害時にも迅速に環境を復元できます。さらに、ローリングアップデートやブルーグリーンデプロイ(新旧環境を並行稼働させて切り替える方法)といった仕組みを活用すれば、システム更新やリリースに伴う計画停止も最小化できます。
AWSでは、AWS Elastic Beanstalk、Amazon ECS/EKS、AWS CodeDeployといったサービスがこれらの手法をサポートしており、計画停止を伴うリリースの影響を抑えることが可能です。運用フェーズでの工夫を重ねることによって、障害からの復旧時間を短縮し、サービスの継続性を高められます。
3. AWS主要サービスで実現する高可用性のベストプラクティス
ここでは、実際にAWSのサービスを活用して可用性を高めるためのベストプラクティスを紹介します。
マルチAZ・マルチリージョン構成による冗長化
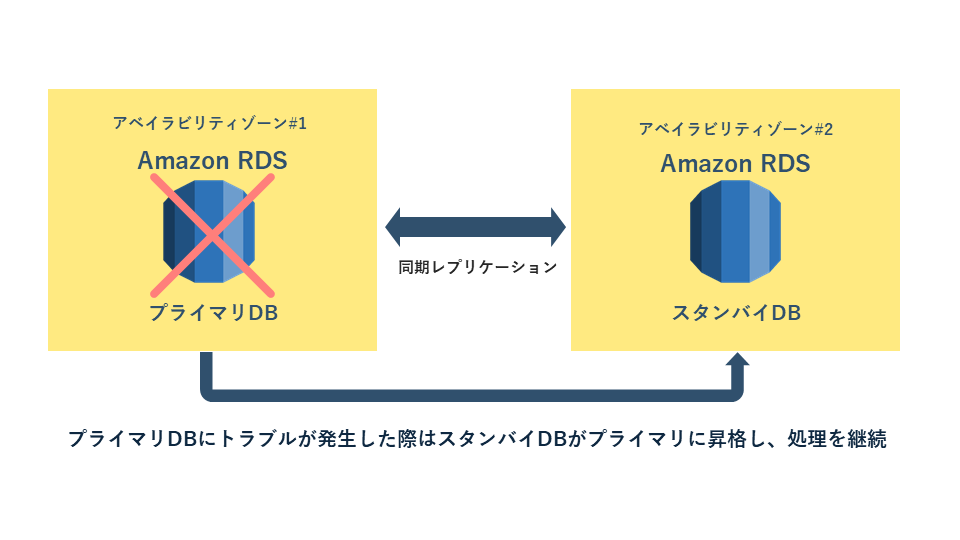
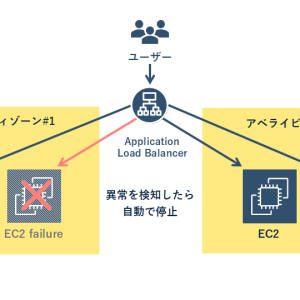
多くのAWSサービスは標準でマルチAZ配置をサポートしています。例えばAmazon RDS(データベースサービス)では、マルチAZ配置を有効にすると、プライマリDBとは別のAZに同期レプリケーションされたスタンバイDBが自動的に用意されます。障害が発生するとスタンバイがプライマリに昇格し、アプリケーション側はほぼ停止時間なしで処理を継続することが可能です。
また、Amazon Aurora(クラウド専用のデータベースサービス)では、データの6つのコピーを3つのAZにまたがって保存しているため、AZ全体の障害にも耐えられる設計となっています。
さらに、リージョンをまたいで冗長化する場合は、Amazon Route 53(DNSサービス)のフェイルオーバールーティングを用いて、稼働しているリージョンへDNSを切り替える構成が一般的です。これにより、大規模災害やリージョン障害にも備えられます。
高耐久性ストレージとレプリケーションによるデータ保護
Amazon S3(オブジェクトストレージサービス)は、保存したデータを複数AZに自動的に分散し、イレブンナイン(99.999999999%)という極めて高い耐久性を実現しています。
バージョニングを有効にすれば、誤削除や上書きからも復旧が可能です。また、クロスリージョンレプリケーションを設定すると、遠隔地にデータを複製でき、広域災害時のディザスタリカバリーにも対応できます。
Amazon EBS(ブロックストレージサービス)も同様に、同一AZ内でデータを自動的にレプリケートし、ディスク障害時に備えています。加えて、EBSスナップショットをS3に保存することで、別AZや別リージョンでの復元も可能です。
これらの仕組みを適切に組み合わせることで、重要なデータの永続性を確保できます。
負荷分散とスケーリングによるリソース最適化
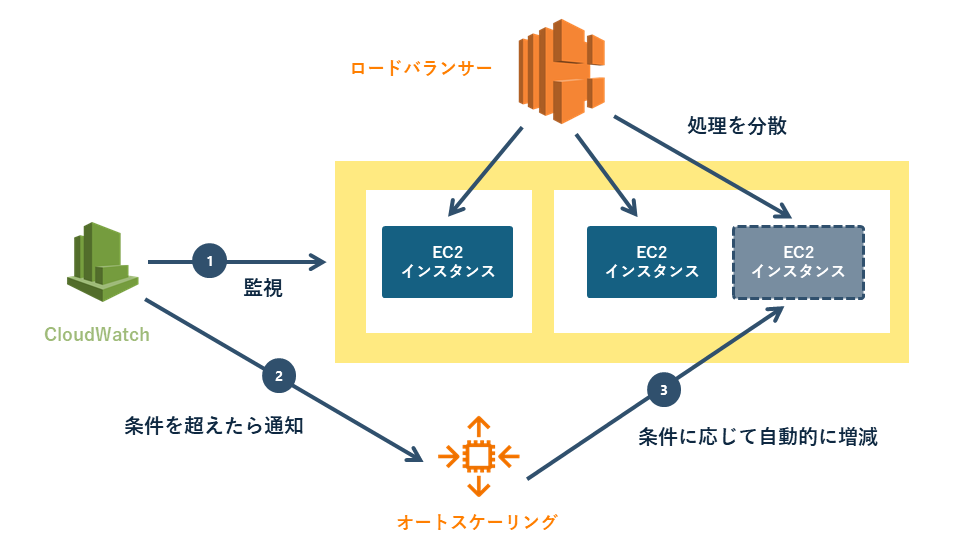
Application Load Balancer(アプリケーション層のロードバランサーサービス)は、HTTP/HTTPSリクエストを解析し、URLパスやホストごとに振り分けることで、複数のサービスやコンテナへ柔軟にトラフィックを分散します。
リアルタイム性が求められるシステムではNetwork Load Balancer(ネットワーク層のロードバランサーサービス)が有効で、TCPやUDP通信を低レイテンシで処理し、数百万リクエスト/秒にも対応可能です。
ロードバランサーと監視サービスであるAmazon CloudWatch、オートスケーリングを組み合わせれば、トラフィックの急増時に自動でEC2インスタンスを増やし、需要が下がれば削減できます。
これらは単なる性能向上にとどまらず、トラフィック集中による障害を未然に防ぐ役割を果たします。
監視・自動復旧・バックアップによる復旧時間短縮
Amazon CloudWatchは、リソースのCPU使用率やレスポンスタイムを常時モニタリングし、しきい値を超えるとアラームを発報します。これをAmazon SNS(通知サービス)と組み合わせれば、運用担当者に即座に通知が届き、初動対応が遅れるリスクを減らせます。
また、EC2(仮想サーバー)にはAuto Recovery機能があり、ハードウェア障害時に同一AZ内の別ホストで自動再起動することが可能です。データベースでは、RDSのマルチAZ構成が障害時に自動フェイルオーバーを行い、ユーザーへの影響を最小化します。
さらに、定期的にEBSスナップショットやRDSバックアップを取得しておけば、システム障害だけではなく人為的な誤操作からも短時間で復旧できます。

4. AWSの高可用性設計におけるポイント
高可用性設計は、単に仕組みを導入すればよいわけではなく、総合的なバランスが求められます。以下の3つは特に重要な観点です。
コストとのバランスを取る
冗長化やレプリケーション、スケーリングなどの仕組みは可用性を高める一方で、リソースの利用量が増えればコストも上昇します。全システムに同じ水準の対策を施すのではなく、業務の重要度に応じて投資レベルを調整することが重要です。
- ページリンク:AWS 請求代行サービス
運用監視と障害対応体制を強化する
設計が万全でも、運用で異常を検知・対応できなければ可用性は維持できません。Amazon CloudWatchなどでリソースを常時監視し、通知や自動復旧を組み合わせて初動を早める仕組みが欠かせません。また、障害対応を属人化させないための体制整備や、外部パートナーの活用も有効です。
定期的なテストと改善サイクルを回す
可用性の仕組みは導入して終わりではありません。フェイルオーバーやバックアップからのリストアのテストを定期的に行い、実際に復旧できるかを検証することが重要です。その結果を反映して手順や監視ルールを見直すことで、運用の成熟度を高められます。
可用性設計とあわせて、AWS全体の構築や構築後に注意すべきポイントも理解しておくことが重要です。詳しくはこちらの記事をご覧ください。
AWS構築ガイド|初心者にもわかる基礎知識と手順、構築後の注意点まで解説
まとめ
可用性は、AWSを活用するうえで最も重視すべき設計要件の一つであり、障害が発生してもシステムを継続できる仕組みづくりが企業の信頼性に直結します。冗長化、耐久性、負荷分散、保守性といった基本の考え方を押さえたうえで、適切なAWSのサービスを組み合わせることで、高可用性を効率的に実現できるでしょう。
ただし、コストの最適化や監視体制の強化、定期的なテストを実施しなければ十分に機能せず、担当者の負担も大きくなります。
ハートビーツは、24時間365日の監視を担うMSPサービス、セキュリティ導入・運用代行、AWS請求代行サービスを提供しています。運用負荷を軽減しながら信頼性とコスト効率を両立させるサポートを行いますので、AWS環境の可用性に課題を感じている場合は、ぜひお気軽にご相談ください。
#フルマネージドサービス for AWS #AWS請求代行サービス #サーバー設計・構築サービス #サーバー監視一次対応サービス