〜トラブルを未然に防ぎ、安定運用を実現するためのヒント〜
運用監視とは、システムの安定稼働を維持するために、障害の予兆や異常を検知し、迅速な対応を行う業務です。日々の運用監視により、大きなトラブルを未然に防ぐことができます。しかし、少人数でシステムを運用している企業では、監視の手が回らなかったり、対応が一部の担当者に偏ってしまったりすることも多いでしょう。
本記事では、運用監視の基本から、防げるリスク、効率的に進めるポイントまでをわかりやすく解説します。現状の運用体制に不安を感じている方は、見直しのきっかけとして参考にしてください。

目次
1. ITシステムの運用監視とは
運用監視とは、サーバーやネットワーク、アプリケーションなど、ITシステム全体の状態を継続的に監視し、異常や障害の兆候を早期に検知・対応するための業務です。サービスの安定運用を支えるために不可欠な要素であり、運用監視が機能していることで、トラブルの拡大や復旧の遅延を防げます。
クラウドやSaaSの利用が当たり前となった今、システムはより複雑かつ多層的になっており、インフラの一部が停止するだけでユーザーへの影響が広がる可能性があります。こうした背景から、日々のシステム状態を正確に把握し、迅速な初動を可能とする運用監視体制の整備が重要視されているのです。
運用監視の主な対象
ITシステムの運用監視における主な対象は以下のとおりです。
サーバー(CPU/メモリ/ディスク)
リソースの使用状況を監視することで、高負荷や容量逼迫といった異常を検知します。突発的なアクセス集中や処理の偏りを捉えるためにも重要です。
ネットワーク(トラフィック/帯域幅/機器の稼働状況)
通信量の増減やネットワーク機器の状態を把握し、トラフィックの偏りや接続の異常を検出します。
データベース(クエリ応答時間/接続数/トランザクション)
クエリ処理の遅延や接続数の急増、処理数の変化などから、パフォーマンスの変動や異常を捉えます。
アプリケーション(応答速度/エラー発生率/処理件数)
アプリケーションの応答やエラーの発生状況を監視し、ユーザー影響につながる可能性のある動作の変化を検知します。
セキュリティ(ログイン状況/不正アクセスの兆候/ファイアウォール設定)
ログイン履歴や通信ログなどを通じて、認証の異常やアクセスパターンの変化といったセキュリティ上の異常を素早く検知します。
2. 運用監視で防げるリスク
運用監視体制が不十分だったり、設定が不適切だったりすると、重大な影響を及ぼす障害やサービス停止につながるおそれがあります。ここでは、適切な運用監視によって防げる主なリスクについて整理します。
異常検知の遅れによる障害拡大のリスク
運用監視体制が整っていないと、システム上の異常に気づくのが遅れ、軽微な不具合が大規模な障害へと発展するリスクがあります。例えば、CPUやメモリの使用率が高止まりしている状態を放置すれば、サービス応答の遅延やダウンタイムにつながりかねません。
リアルタイムでの監視や閾値設定が適切に機能していれば、こうした兆候を早期に把握し、影響が小さいうちに対処できます。
障害対応の遅延によるサービス停止リスク
アラートの通知が遅れたり、誰が対応すべきかのルールが曖昧だったりすると、初動対応に時間がかかり、障害が長引くおそれがあります。状況によっては、サービス自体が一時的に利用できなくなる事態に発展するケースもあります。
特に、夜間や休日に障害が発生した場合、担当者への連絡がつかず、対応が大幅に遅れることも珍しくありません。障害発生時に必要な情報が即座に共有され、誰が何をすべきかが迷わず判断できる体制が整っていれば、被害を最小限に抑え、サービス停止を回避できます。
顧客満足度や信頼の低下によるビジネス損失リスク
システム障害がユーザーに直接影響を及ぼすような事態になれば、顧客の満足度や企業への信頼が損なわれます。特に、ECサイトやSaaS、Webサービスなど、リアルタイム性が求められる業態においては、サービス停止が売上や解約率に直結するケースもあるでしょう。
継続的な監視を通じて障害の発生を抑え、安定したサービス提供を維持することは、結果的にビジネスの継続性と成長にもつながる重要な取り組みといえます。
3. 運用監視の進め方
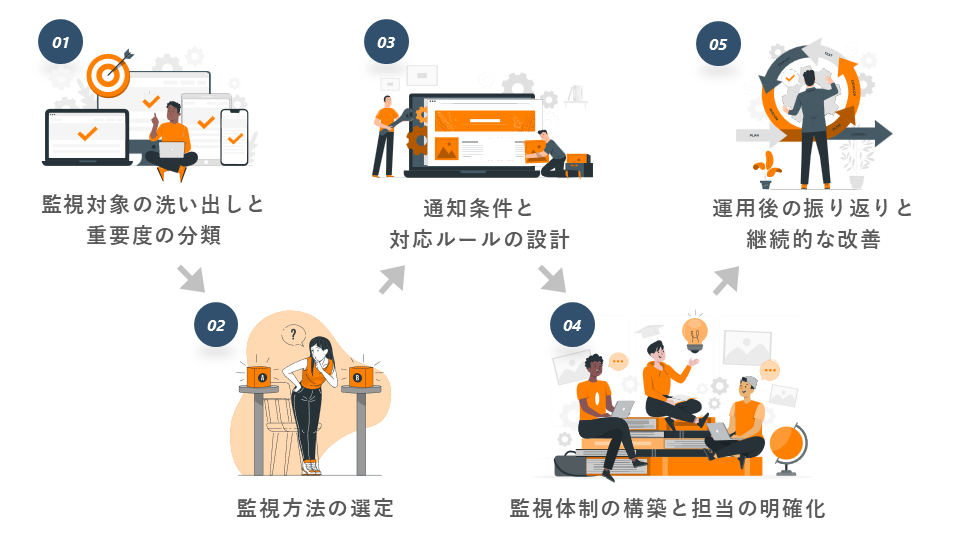
運用監視は、ツールを導入すればすぐに機能するものではなく、自社のシステム構成や体制に合わせた設計と運用プロセスの整備が不可欠です。ここでは、実際に運用監視体制を構築・改善していく際に押さえておくべき5つのステップを紹介します。
1. 監視対象の洗い出しと重要度の分類
まずは、自社システムのなかでどの機能・構成要素を監視対象とするかを明確にします。サーバー、ネットワーク機器、アプリケーション、データベースなど、対象範囲を網羅的に洗い出しましょう。
そのうえで、業務への影響度に応じて各対象の重要度を分類します。すべてを同等に扱うのではなく「止まると致命的な箇所」から優先順位をつけて整理しておくことで、後続の監視設計や対応方針の検討をスムーズに進められます。
2. 監視方法の選定
対象ごとに、どのような監視方法を適用するかを決めます。リソース使用率の閾値監視、死活監視、ログ監視、外形監視、ジョブ監視など、監視の種類は多岐にわたります。
クラウド上のサービスやマルチリージョン構成を前提とする場合、従来のサーバー中心の監視設計とは異なる視点が求められることもあるため注意が必要です。例えば、サーバーレス環境ではCPUやメモリといったリソースの使用率ではなく、関数の実行回数やエラーレート、スロットリング(利用が急増した際に、システムが自動的に処理を制限する仕組み)の有無といったメトリクスを中心に監視を設計する必要があります。監視方法が定まったら、それを実現できるツールやサービスの選定もあわせて検討しましょう。
3. 通知条件と対応ルールの設計
次に、アラート通知の条件や対応ルールを設計します。どのタイミングで、誰に、どのような手段で通知を出すかを決めておかないと、アラートを受け取っても対応が遅れたり、見逃されたりするおそれがあります。
すべてのアラートに即対応する必要はありません。「要確認」「要対応」「緊急」などのレベル分けを行いましょう。これにより、チームの負担を減らしつつ、対応の優先順位を明確にできます。
4. 監視体制の構築と担当の明確化
設計した内容を実際の体制に落とし込みます。どの時間帯に誰がアラート対応を担うか、対応できない時間帯がある場合はどう代替するかなど、運用現場で具体的に回る体制を整えることが重要です。
特に、夜間・休日対応の有無、一次対応とエスカレーションの分担、外部委託先との連携などは、属人化や対応遅延を防ぐためにも明確にしておくべきポイントです。
5. 運用後の振り返りと継続的な改善
運用監視体制は、一度構築して終わりではありません。運用を継続するなかで「アラートが多すぎる」「通知されても対応に結びついていない」といった課題が見えてくることも多くあります。
定期的にアラートの発生傾向や対応状況を振り返り、閾値の見直しや通知条件の調整、手順書の更新などを行いましょう。より実態に即した監視体制へと進化させることができます。

4. 運用監視を行う際の注意点
ここでは、運用監視を行う際によく見られる3つの注意点を解説します。
アラート過多による見逃しの発生
監視対象やルールを過剰に設定すると、アラートが頻発し、通知が埋もれて本当に危険な兆候を見逃しかねません。重要度や対応優先度を明確に区分し、不要なアラートは抑制することで、精度の高い運用を実現できます。
閾値設定の甘さによる対応遅れ
CPU使用率やレスポンスタイムなどの閾値を曖昧に設定していると、異常が発生してもアラートが出ず、対応が遅れるおそれがあります。「とりあえずデフォルト設定のまま使っている」という状態では、監視が機能しないことも少なくありません。システム特性や利用状況に応じた適切な閾値を見極め、定期的に見直す必要があります。
監視対象の属人化と対応体制の不備
監視設定やアラート対応の知識が特定の担当者に偏っていると、運用が属人的になり、引き継ぎや体制変更の際に問題が発生するおそれがあります。監視設定のドキュメント化や対応フローの整備を通じて、チーム全体で共有・運用できる体制を構築しておきましょう。
5. 運用監視を効率化するためのポイント
ここでは、担当者の負荷が高まりやすい運用監視を効率化するためのポイントを解説します。
自動化ツールを活用したアラート集約と分析
監視の効率化を図るうえで、自動化ツールの活用は欠かせません。複数システムからのアラートを自動で集約し、重要度や発生傾向を分析できる基盤が整えば、対応の優先順位づけや傾向把握が格段にしやすくなります。
さらに、ツールによっては特定のアラートに対して自動的に復旧処理を実行する機能を備えており、人的リソースを使わずに初動対応を済ませられる場面も増えています。
通知の整理とフローの明確化
どの通知が「確認で済むもの」か「即時対応すべきもの」かをあらかじめ定義し、レベル分けしておくことで、現場の対応効率が大きく向上します。また、誰がいつ、どの手段で通知を受け取り、どこまで対応するのかといった通知フローの明確化も重要です。
属人化や対応遅延を防ぐために、対応ルールを簡潔に整理し、ドキュメントとして共有しておくとよいでしょう。
初動対応のテンプレート化と継続的な改善
アラート発生時の初動が遅れる原因のひとつが「何をすればよいかわからない」状態です。よくあるアラートに対しては、あらかじめ初動対応の手順やチェック項目をテンプレート化しておくことで、対応の標準化とスピードアップを図れます。
さらに、障害対応が完了したあとは振り返りを行って「対応に無駄がなかったか」「設定は適切だったか」などを確認し、設定や手順の継続的な改善に反映していくことが重要です。
外部パートナーとの分担による負荷分散
運用監視業務を社内だけで担おうとすると、24時間体制でのアラート監視や障害発生時の初動対応、監視設定の調整作業などに多くの工数を取られ、ほかの業務に影響が出てしまうケースもあります。こうした状況を避けるには、外部パートナーと業務を分担し、本来の業務に支障が出ない体制を整えることが重要です。
例えば、アラートの一次対応や夜間・休日の監視といった領域を外部に任せることで、コア業務に集中できる環境を確保しやすくなります。
まとめ
運用監視はシステムの安定稼働を支える重要な業務ですが、限られた人員での対応や兼任体制では、対応遅れや業務負荷の増大などを招きやすくなります。効率的な運用監視体制を実現するには、監視設計や通知ルール、初動対応の整理に加え、自動化や外部パートナーの活用が欠かせません。
ハートビーツのMSPサービスは、24時間365日の監視から障害対応、原因の切り分けまで踏み込んで対応できるのが特長です。ナレッジを持ったエンジニアが柔軟に対応し、実行力のある運用体制を構築します。確かな技術力と経験でサポートし、運用負荷の軽減とインフラコストの最適化、業務の安定化を支援しますので、ぜひご相談ください。