社内システム用のコンテナ基盤をDockerからマネージドKubernetesサービスであるAmazon EKS(以下「EKS」と略す)とAzure Kubernetes Service(以下「AKS」と略す)に移設しました。本記事では、マルチクラウドでのKubernetesの設計と運用について弊社での事例をご紹介します。
]]> コンテナ基盤の移設にあたって課題
弊社では多くの社内向けサービスをDockerで運用していましたが、次第に重要なアプリケーションも動き始め可用性に課題が見え始めました。弊社では24時間/365日の有人監視・運用保守サービスを提供しており、一つのクラウドプロバイダーの障害によって可用性を損なわない構成が必要でした。また、コンテナイメージや設定ファイルを手動で更新する運用をしており、効率性や人為的ミスのリスクなどの運用管理の課題もありました。
方針
課題を改善するにあたり以下のように方針を定めました。
・可用性
AWSとAzureで冗長化し、Active/ActiveもしくはActive/Standby(※1)で動かせるようにする。負荷分散はDNSラウンドロビンで行う。
※1:Active/Standbyは、障害時にフェイルオーバーせず手動で切り替える運用です。
・運用管理
各アプリケーションで共通したCI/CDパイプラインを構築し、効率的で信頼性の高いデプロイフローを設計する。マルチクラウドでのコンテナ管理のため、標準化されたコンテナプラットフォームであるKubernetesを利用する。また、Kubernetesの運用コストを考慮しマネージドKubernetesサービスを利用する。
可用性を担保するためのマルチクラウド構成
冗長化したクラスター間の永続データの共有には、マルチクラウド間でレプリケーションしたデータベースサーバーを利用しています。また、弊社社内システムのAWSの環境とAzureの環境はサイト間VPNで接続されているため横断したアクセスが可能です。データベースサーバーについてはマルチクラウド構成におけるMySQL Group Replicationの利用事例紹介を、クラウド間のVPNについてはWireGuardによるマルチクラウド構成VPNの事例紹介をご参照ください。
可用性の担保による弊害
ここでは可用性の担保のためにコンテナ基盤をマルチクラウド構成としたことによって生じた問題について紹介します。
弊社のデータベースサーバーはActive/Passiveで運用しており、レプリケーションされたうちの1台のデータベースサーバーに対して同時にアクセスする必要があります。そのためアプリケーションをActive/Active構成とすると必然的にクラウドをまたいだアクセスが発生します。これにより、あるオープンソースソフトウェアの特定のページ表示に約20秒の遅延が発生しました。このページは表示するために大量のクエリを実行しており、そのためネットワークレイテンシの影響を最大限に受けていることが遅延の原因でした。
このサービスは可用性が求められないためActive/Standby構成にして回避しましたが、アプリケーションの作りによっては大きくパフォーマンスが悪化する例として挙げました。これまでマルチクラウド構成で動いているシステムでパフォーマンスは問題になりませんでしたが、よりシビアにパフォーマンスが求められる環境では、このあたりのトレードオフはより大きな課題となります。
運用管理のためのCI/CDパイプライン
Argo CDとGitLab CI/CDを利用してCI/CDパイプラインを構成しています。GitOpsと呼ばれるCDの手法です。GitOpsについてはGitOpsを提唱したWeaveworks社のGuide To GitOpsやWhy is a PULL vs a PUSH pipeline important?が分かりやすく、導入するうえで参考になりました。
Argo CD
公式ドキュメントから引用すると、Argo CDとは「Kubernetes用の宣言的なGitOps継続的デリバリーツール」です。Kubernetesクラスター内にArgo CDをデプロイして利用します。
GitLab CI/CD
GitLabとは、GitLab社が開発しているSCM(ソースコード管理)ツールで、CI/CD (Continuous Integration/Continuous Delivery)機能があります。弊社では社内にセルフホストしているGitLabサーバーがあるためこちらを利用しています。
デプロイフロー
以下はアプリケーション更新時のデプロイフローです。
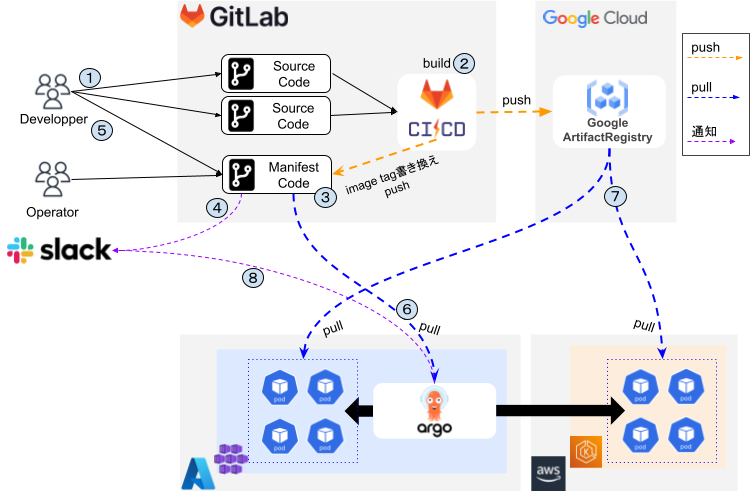
※GitLabはセルフホストしている社内用のGitLabサーバーを指しています。
図内の番号の説明は以下です。
- 各アプリ用レポジトリへタグをプッシュする
- GitLab CI/CDがトリガーされる
- イメージをビルドし、コンテナレジストリにプッシュする
- マニフェストのイメージタグを書き換える(Kustomize edit set image)
- マージリクエストの作成(※2)
- 「2-3.」によりGitLab CI/CDがトリガーされる
- kubeconformでマニフェストの検証を行う
- マージリクエストが作成された旨をSlackへ通知する(CIによる検証が失敗した場合も同様)
- 手動でマージする
- Argo CDが変更を検知しマニフェストをプルする
- コンテナのデプロイがはじまり、イメージをプルする
- Argo CD Notificationsでデプロイ成功可否をSlackへ通知する
Argo CDとGitLabのSlack連携を利用し、見るべき場所を集約し簡潔なフローとなるようにしました。「3-1.」のkubeconformによる検証はこのフローで失敗することはありませんが、マニフェスト新規追加・変更時の検証のために利用しています。
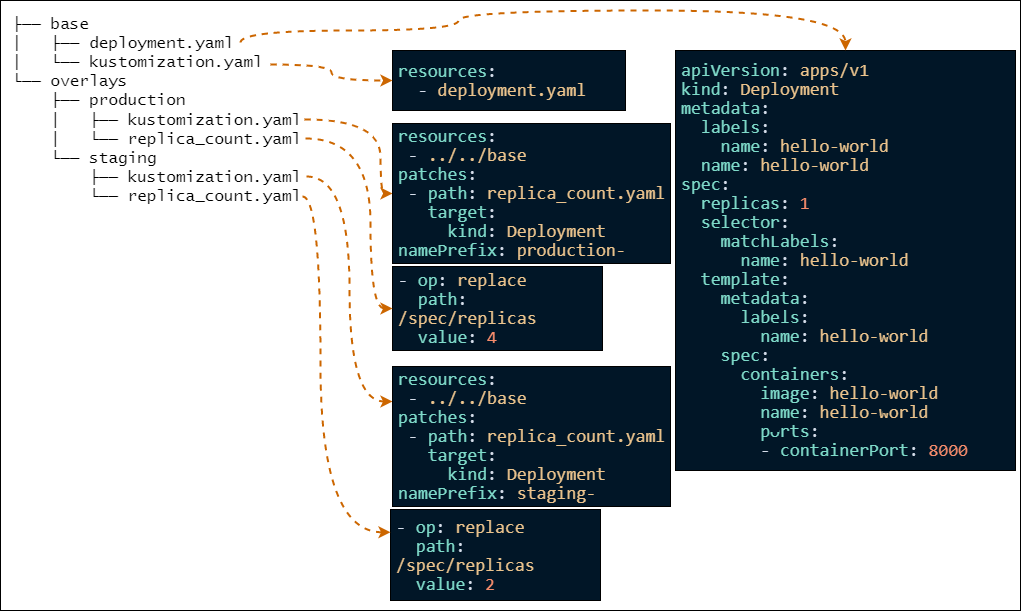
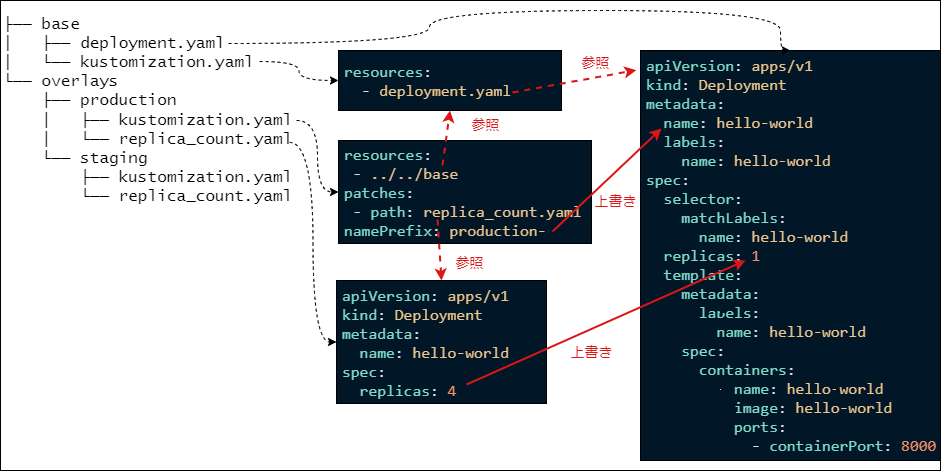
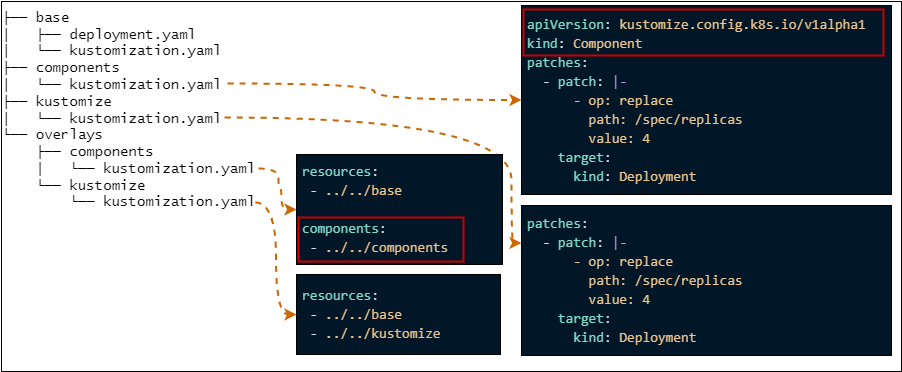
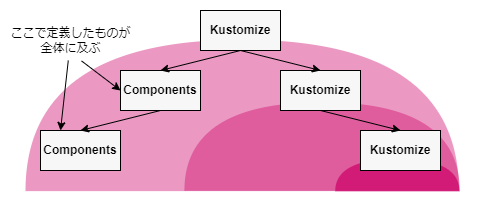
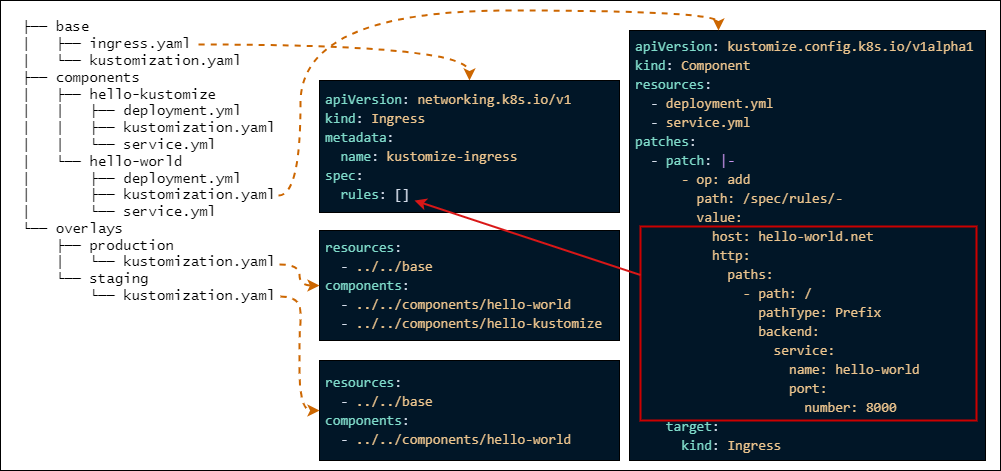
Argo CDはAKSにのみデプロイし、1つのArgo CDで全体を管理しています。マニフェストはKustomizeを利用してモノレポ(※3)でマルチクラスター環境を管理しています。KustomizeのComponentsを利用することでマニフェストを共通化させ、Active/ActiveとActive/Standbyを簡単に切り替えることができるようにしています。この方法についてはKustomizeとComponents の利用例の紹介という記事で紹介しています。
※2:git pushで「-o merge_request.target=main -o merge_request.create」オプションを付けると同時にマージリクエストを作成できます。この例では、mainブランチに対してのマージリクエストを作成します。
※3:1つのレポジトリで複数プロジェクトを管理することです。
その他利用技術
ここまで紹介した中で触れられなかったKubernetesの運用を行う上で利用している技術について紹介します。
Ingressコントローラー
Ingressコントローラーは、Kubernetes環境用のロードバランサーを管理するリソースです。
Ingressコントローラーを管理上の理由からEKSとAKSで共通化したいため、NGINX Ingress Controllerを採用しました。NGINX Ingress Controllerは、NGINXが管理しているものとKubernertesが管理しているものと2つあります。今回はKubernetesコミュニティが管理しているNGINX Ingress Controllerを利用しています。
EKSとAKSの負荷分散はDNSラウンドロビンで行う都合上CNAMEレコードが利用できないため、Aレコードを利用するために固定のグローバルIPアドレスが必要でした(※4)。 EKSのNGINX Ingress Controllerでは、AWSのロードバランサーの1つであるNetwork Load Balancerを利用しています。
社内利用のため送信元IPアドレスによるアクセス制御が必要なためNLBの後方へIPアドレスを伝える必要がありました(※5)。NLBではProxy protocolを利用できるため有効にしようとしましたが、Helmから有効化できませんでした。(※6)やむを得ずClient IP preservationを利用しましたが、Client IP preservationは対象サブネットをパブリックサブネットにする必要があります。つまりコンテナが外部に接続するにはノードごとにパブリックIPアドレスが必要で、動的パブリックIPアドレスを付与することになります。そのため、別システムで「EKSからの通信を許可したい」というケースに対応できなくなりました。Argo CDはもう一方のKubernetesクラスターとGitLabに接続するため、送信元IPアドレスによるアクセス制御をするには固定IPアドレスが必要でした。そのためArgo CDはAKSにデプロイする構成となっています。
※4:EKSで利用するNGINX Ingress Controllerでは利用するロードバランサーの種類をNetwork Load BalancerとClassic Load Balancerから選択できます。
※5:構築当初にNLBはセキュリティグループをサポートしていませんでした。アクセス制御だけを目的とする場合、送信元IPアドレスの伝達は不要です。
※6:2023年4月ごろに構築したため、現在は解消されている可能性があります。
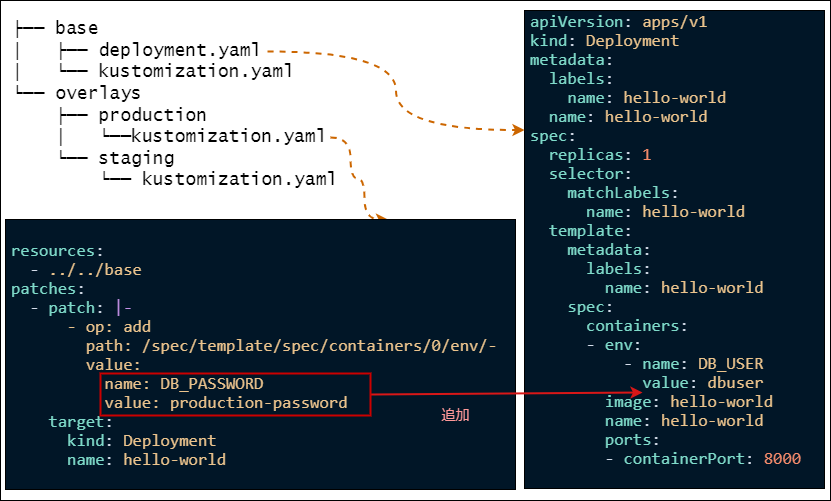
Sealed Secret
Sealed Secretはマニフェストのデータの暗号化のためのサービスです。環境変数や設定ファイルに機密情報を含めたい場合に利用します。他にも同等の機能を提供するオープンソースはありますが、Sealed Secretは情報の取り扱いをGitリポジトリとKubernetesクラスター内で完結できるのが特徴です。異なるタイプのものだとAWS Key Management ServiceやAzure Key Vaultといったクラウドの鍵管理サービスを利用するものがあります。弊社ではマルチクラウド構成にしていることもあり共通で利用できるSealed Secretを採用しました。Sealed Secretをマルチクラスターで利用するには、共通の秘密鍵を利用する必要があります。
AWS Distro for OpenTelemetry
EKSで取得できるデフォルトのメトリクスは十分でないため、AWS Distro for OpenTelemetryを導入しました。 インストール方法はAWS Distro for OpenTelemetry の使用のとおりです。デフォルトの設定だと多くの量のメトリクスが取得されるため、ConfigMapを修正し必要なメトリクスのみを取得しています。
さいごに
このプロジェクトは「AKSとEKSを使っていい感じにマルチクラウドのKubernetes基盤を作る」ということだけ決まっており、ざっくりとした構想図からはじまりました。Kubernetesを1から学ぶところからスタートしましたが、弊社での用途としては良い構成になったと思います。一般的な構成ではありませんが、一部分だけでもこの記事が参考になれば幸いです。
]]>