こんにちは、滝澤です。
前回の記事『WireGuardによるマルチクラウド構成VPNの事例紹介』に引き続き、社内事例を紹介します。
弊社ハートビーツではMSP(Managed Service Provider)サービスの可用性向上のために、社内基盤をマルチクラウド構成で運用しています。
複数のクラウド拠点のネットワーク間をWireGuardというVPNトンネルのソフトウェアで接続しています。
さらに、リレーショナルデータベース管理システムにはMySQLを利用しており、MySQLのレプリケーション機能の一つであるGroup Replicationを使って拠点内および拠点間における冗長化を行っています。
今回はこのMySQL Group Replicationの利用事例を紹介します。
行っていることをまとめると次のようになります。
- マルチクラウド構成(Azure, AWS, GCP)において、MySQLサーバーの冗長化としてMySQL Group Replicationを利用している。
- マルチプライマリーモード(multi-primary mode)で運用しており、アプリケーションからは同じ拠点内のMySQLサーバーをActive/Passive構成として利用している。
- MySQL用の監視プラグインに対して、MySQL Group Replicationのステータス監視の機能を開発して追加した。
MySQL Group Replicationとは
MySQL Group Replication(以降「グループレプリケーション」と記す)はMySQLのレプリケーション実装の一つです。
特徴の一つとしては、レプリケーションを行うグループのメンバー管理を行うことです。シングルプライマリーモード(single-primary mode)では、プライマリーノード(更新可能なノード)の選出が自動で行われます。プライマリーノードの障害時には他のノードが自動でプライマリーに選出され昇格します。
さらに、マルチプライマリーモード(multi-primary mode)では、すべてのノードがプライマリーノードとなり更新が可能になります。
グループレプリケーションについての詳細は公式サイトの文書をご覧ください。
- [Chapter 18 Group Replication
Table of Contents](https://dev.mysql.com/doc/refman/8.0/en/group-replication.html) (MySQL)
なお、従来のレプリケーションに比べて、様々な制約がある点には注意してください。
以降、弊社での事例を紹介します。
背景
弊社がラックを借りているデータセンターが閉鎖することになったのがきっかけです。
2019年4月から調査と計画を始め、新しい社内システム基盤をマルチクラウド構成でクラウド上に構築し、その基盤に現在運用しているサーバーを移設する方針を決めました。
移設元のシステムではデータベース管理システムにMySQLを利用していたため、移設先でもMySQLを利用することは決定事項でした。
マルチクラウド構成の各拠点にMySQLサーバーのノードを配置するために、レプリケーションにはグループレプリケーションを利用する方針で検証を行い、制約はあるものの実運用上は問題ないと判断して、採用しました。
2019年10月から設計・構築に着手し、2020年2月末にデータセンターからの移設がすべて完了しました。
MySQLサーバーは2020年2月上旬から運用を開始しており、現時点(2020年8月下旬)で6ヶ月半運用していることになります。
事前検証
2019年7月に検証を行いました。このときのバージョンは8.0.16でした。
まず、次の公式サイトの文書を読んで、設定パラメータの確認や制約の確認を行いました。
- [Chapter 18 Group Replication
Table of Contents](https://dev.mysql.com/doc/refman/8.0/en/group-replication.html) (MySQL)
次に、設定パラメータを変えながら、障害注入試験を行い、どのような挙動になるか、どのように復旧するかの確認を行いました。
特に各クラウド拠点の拠点間をソフトウェアVPNで接続しているため、VPNルーターの仮想マシン(インスタンス)障害やネットワーク障害がそれなりの頻度で発生することを想定していました。そのため、運用上の手間を考え、自動復旧できるかが課題の一つでした。
もちろん、ネットワークパーティション(ネットワークの分断)が発生したときに、スプリットブレイン(疎通が分断された両方のノード共にサービスの継続が行われてしまうこと)が起きないことも確認事項の一つでした。
検証結果の雑なメモの一部を転記します。
– 障害注入試験の結果
– パラメータを適切に設定すれば以下の障害から自動復旧できることがわかった。
– ホストダウン(正常終了)からの復帰
– ホストダウン(異常終了)からの復帰
– ネットワークパーティションからの復帰
– ネットワーク瞬断からの復帰
– ネットワークパーティション発生後
– 多数側(クオーラム(定足数)が取得できたグループ)では参照・更新共に継続できる。
– 少数側(クオーラム(定足数)が取得できなかったグループ)では参照のみになり、更新できなくなる。
– 細かく分断され、多数側(クオーラム(定足数)が取得できたグループ)が存在しないときには、全てのノードがERRORステータスになる。ネットワークが復旧しても、自動復旧はできなくなる。
– 構成の検討
– 3拠点3ノード案: 1 + 1 + 1
– 各拠点1ノードの場合は、プライマリ拠点のMySQLサーバーのノード障害やメンテナンスダウンが発生するとセカンダリ拠点へのサービスのフェイルオーバーが必要になってくる。これはあまり好ましくはない。
– 3拠点5ノード案: 2 + 2 + 1
– プライマリ拠点およびセカンダリ拠点においてMySQLサーバーをそれぞれ2ノードで動かしておくと、拠点間のサービスのフェイルオーバーなしにノード障害やメンテナンスダウンへの対応はできる。
– ロードバランサーやプロキシーが必要になる。
MySQLのバージョンと設定
MySQLは構築時(2020年1月)における最新バージョン8.0.19を利用しています。
基本的には公式サイトの文書の通りに設定を行って運用しています。
- [Chapter 18 Group Replication
Table of Contents](https://dev.mysql.com/doc/refman/8.0/en/group-replication.html) (MySQL)
構成については後述しますが、3拠点5ノードの構成にしており、グループレプリケーションのマルチプライマリーモードを利用しています。
設定ファイルの一部を紹介します。パラメータは実際の値からは一部書き換えています。
次の設定は、どのような構成でも大して変わらないでしょう。
# Storage Engines
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
# Replication Framework
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
binlog_checksum=NONE
# Group Replication Settings
plugin_load_add='group_replication.so'
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot=OFF
group_replication_local_address="192.0.2.1:33061"
group_replication_group_seeds="192.0.2.1:33061,192.0.2.2:33061,198.51.100.1:33061,198.51.100.2:33061,203.0.113.1:33061"
group_replication_ip_whitelist="192.0.2.0/24,198.51.100.0/24,203.0.113.0/24"
group_replication_bootstrap_group=OFFなお、group_replication_start_on_bootは構築時のみOFFを設定しています。運用を始めた後はレプリケーショングループに自動参加させるためにONに設定し直しています。また、group_replication_group_seedsに記述したグループメンバーの各ノードについては/etc/hostsファイルに記述しています。group_replication_group_seedsにホスト名では無くIPアドレスを記述しているのはIPv4射影アドレスに関するトラブルが生じたためです。
次の設定は、マルチプライマリモードを有効にするために、シングルプライマリーモードを無効にしている設定です。
group_replication_single_primary_mode=OFF次の設定は、タイムアウトおよび自動参加に関する設定です。
各クラウド拠点の拠点間をソフトウェアVPNで接続しているため、時々発生するネットワークの数秒間の断を許容するためにタイムアウトを長くしています。また、仮想マシン(インスタンス)周りの障害への対応として、仮想マシンの停止および起動を行った際に自動参加できるようにしています。
group_replication_member_expel_timeout=30
group_replication_unreachable_majority_timeout=30
group_replication_exit_state_action=READ_ONLY
group_replication_autorejoin_tries=80次の設定はオートインクリメントの設定です。マルチプライマリーモードの5ノードで運用しているため、通常であればgroup_replication_auto_increment_incrementの値をノード数に設定すべきですが、実運用上は1ノードからのみ更新を行うため、1に設定しています。また、アプリケーションの採番上、番号が跳ぶのは不都合があるためでもあります。
group_replication_auto_increment_increment=1次の設定はレプリケーションの一貫性に関する設定です。group_replication_consistencyはデフォルトのEVENTUALに設定しています。社内システムのアプリケーションは更新系クエリーの頻度が低く、さらに通常は1ノードのみからしか更新と参照を行わないため、結果整合性が担保できればよいと考えています。
group_replication_consistency=EVENTUAL構成
構成は次の図のようになります。
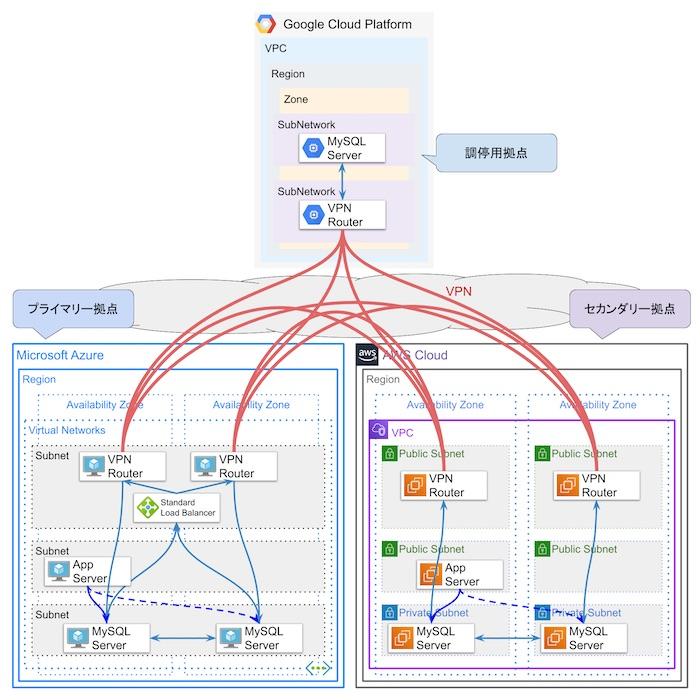
クラウドの拠点として次の3拠点を利用しています。
- Azure 東日本リージョン: プライマリー拠点
- AWS 東京リージョン: セカンダリー拠点
- GCP 東京リージョン: 調停用拠点
Azure 東日本リージョン
Azure東日本リージョンをプライマリー拠点として利用しています。社内システムのサービスはこの拠点で動かすことになります。
MySQLサーバーは2つのゾーンにそれぞれ1つずつ配置しており、合計2個のMySQLサーバーが動いています。
マルチプライマリーモードであるため、本来は2個のMySQLサーバーのどちらを利用してもよいです。
しかし、MySQLサーバーがアクティブ/パッシブ構成であるかのように、通常時には同じアベイラビリティゾーンにある方を、障害発生時には別のゾーンにある方を利用してくださいとアプリケーションの担当者には案内を出しています。
MySQLサーバーへのアクセスを振り分けるためには、MySQL用のプロキシーが必要となります。
共通で利用するMySQL用のプロキシー専用のホストを別途用意するという考えもありますが、プロキシーそのものが障害点となり得るため、プロキシーの可用性をさらに検討する必要が出てきます。
そのため、fate-sharing model(運命共有モデル)を参考に、アプリケーションと同じホスト上にプロキシーを配置することにしました。アプリケーションとプロキシーはそのホストの障害時には一緒に利用できなくなるため、可用性の検討についてはシンプルになります。
その結果として、アプリケーションの担当者はプロキシーのミドルウェアとしてHAProxyを同じホスト上に導入していました。
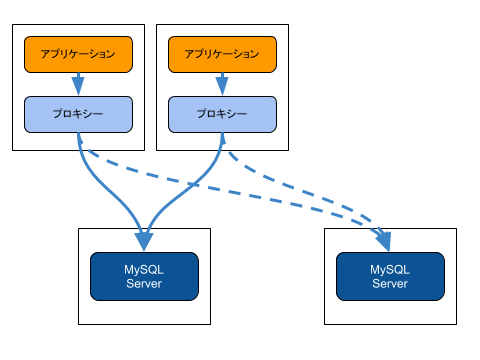
なお、fate-sharing model(運命共有モデル)については次の論文を参照してください。
- The Design Philosophy of the DARPA Internet Protocols (ACM SIGCOMM Computer Communication Review Paper Retrieval)
AWS 東京リージョン
AWS東京リージョンをセカンダリー拠点として利用しています。高可用性が要求される社内システムの場合は、アクティブ/アクティブ構成あるいはアクティブ/パッシブ構成として、プライマリー拠点に加えて、こちらの拠点でも動かします。
MySQLサーバーは2つのゾーンにそれぞれ1つずつ配置しており、合計2個のMySQLサーバーが動いています。
利用方法はプライマリー拠点と同様です。
GCP 東京リージョン
GCP東京リージョンを調停ノード用の拠点として利用します。この拠点では社内システムのサービスは動かしません。
MySQLサーバーは1つのゾーンに1つ配置しています。
分散システムのクオーラム(定足数)の判定に利用するためのノードをこの拠点に配置します。
AzureやAWSのリージョンやゾーンにおいて何らかの障害によりネットワークパーティションが発生した場合に、この拠点のノードにアクセスできるノード側がクオーラムを満たし、マジョリティ(過半数)になり、サービスを継続できることになります。本システムではクラウド事業者のリージョン規模での障害が発生してもサービスを継続できるようにすることを想定しています。
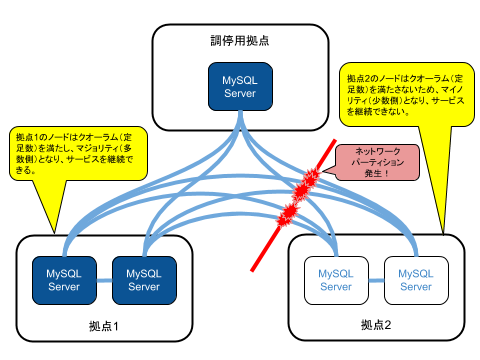
また、この調停用拠点が一時的に利用不可になっても、アプリケーションからのアクセスは無いため、問題ありません。
マルチプライマリーモード
今回の構成ではシングルプライマリーモードではなく、マルチプライマリーモードを採用しました。主な理由は次の通りです。
シングルプライマリーモードでは、プライマリーノードが必ずしもサービスを提供しているアプリケーションと同じ拠点内のノードになるとは限らないためです。
アプリケーションとプライマリーノードのMySQLサーバーの拠点が異なると、ネットワークのレイテンシーが増えるため、結果としてはアプリケーションの応答遅延につながります。
マルチプライマリーモードの場合は、アプリケーションは同じ拠点内のMySQLサーバーにアクセスすればよいので、不要なレイテンシーの増加はありません。
また、マルチプライマリーモードの制約として下記のようなデッドロックのリスクがあります。
Multi-primary Mode Deadlock. When a group is operating in multi-primary mode, SELECT .. FOR UPDATE statements can result in a deadlock. This is because the lock is not shared across the members of the group, therefore the expectation for such a statement might not be reached.
このリスクへの対応としては、アプリケーションが一つのMySQLサーバーのみを利用するようにして、そのMySQLサーバーの障害時に同じ拠点内の別のMySQLサーバーを利用するといった、アクティブ/パッシブ構成であるかのように利用することにしました。
しかし、高可用性のためにアプリケーション自体が2拠点にそれぞれ配置されている場合は、アプリケーションをアクティブ/パッシブ構成で運用していれば問題は無いですが、アクティブ/アクティブ構成で運用しているとこのリスクは残ったままとなります。
弊社の場合は、データの更新頻度が高いアプリケーションを利用していないことと、クリティカルな用途でもない(更新に失敗したらやり直せばよい)ため、実質的には問題ないだろうということで運用しています。
グループレプリケーションの監視
グループレプリケーションのステータスの監視にはmackerelio/go-check-plugins/check-mysqlをforkして、グループレプリケーションのステータス監視機能を追加したものを利用しています。
- ttkzw/go-check-plugins/check-mysql (GitHub)
もし、利用したい方がいらっしゃいましたら、check-mysql-group-replicationブランチの方を利用してください。
group-replicationサブコマンドのオプションは次の通りです。
group-replication subcommand
Checks the status of MySQL Group Replication.
-H, --host= Hostname (default: localhost)
-p, --port= Port (default: 3306)
-S, --socket= Path to unix socket
-u, --user= Username (default: root)
-P, --password= Password [$MYSQL_PASSWORD]
--local-hostname= Local hostname as a group member. See performance_schema.replication_group_members.
--local-port= Local port number as a group member. See performance_schema.replication_group_members. (default: 3306)
-g, --group-members Detect anomalies of other group membersデフォルトでは自ノードのステータスの監視を行います。
azure-db01ノードにおいて、グループメンバーのステータスが次のようになったとします。
mysql> SELECT MEMBER_HOST,MEMBER_STATE FROM performance_schema.replication_group_members;
+-------------+--------------+
| MEMBER_HOST | MEMBER_STATE |
+-------------+--------------+
| azure-db01 | ONLINE |
| azure-db02 | ONLINE |
| aws-db01 | ONLINE |
| aws-db02 | ONLINE |
| gcp-db01 | ONLINE |
+-------------+--------------+
5 rows in set (0.00 sec)このときは、azure-db01ノードのステータス監視の出力は次のようになります。
MySQL Group-replication OK: ONLINEazure-db01ノードにおいて、グループメンバーのステータスが次のようになったとします。
mysql> SELECT MEMBER_HOST,MEMBER_STATE FROM performance_schema.replication_group_members;
+-------------+--------------+
| MEMBER_HOST | MEMBER_STATE |
+-------------+--------------+
| azure-db01 | ERROR |
+-------------+--------------+
1 row in set (0.00 sec)このときは自ノードのステータスがERRORになったのでステータス監視の出力は次のようになります。
MySQL Group-replication CRITICAL: ERROR-gオプションを付けると、自ノードが認識している他のグループメンバーのステータスの監視も行います。ノード間で相互のステータスの認識が異なることが発生しているため、この機能を付けました。
azure-db01ノードにおいて、グループメンバーのステータスが次のようになったとします。
mysql> SELECT MEMBER_HOST,MEMBER_STATE FROM performance_schema.replication_group_members;
+-------------+--------------+
| MEMBER_HOST | MEMBER_STATE |
+-------------+--------------+
| azure-db01 | ONLINE |
| azure-db02 | ONLINE |
| aws-db01 | ONLINE |
| aws-db02 | UNREACHABLE |
| gcp-db01 | ONLINE |
+-------------+--------------+
5 rows in set (0.00 sec)このときは、azure-db01ノードのステータス監視の出力は次のようになります。
MySQL Group-replication WARNING: ONLINE. Anomalies were detected in other group members: aws-db02:3306 UNREACHABLEこのようにして、グループメンバーのステータスも監視できるようになっています。
実は、upstreamにこの機能のPull Requestはまだ送っていません。この機能を実装した当時はグループレプリケーションのステータス監視はこれでよいのか迷いがあり、運用しながら調整していこうと考えていたためです。半年ほど経過しましたが、特に問題なさそうなので、そのうち手が空いたらPull Requestでも送ってみようかなと思っています。
運用状況
マルチクラウド構成におけるグループレプリケーションが安定運用しているかという話を最後に紹介しましょう。
気になった点はあるものの、結論としては安定運用できているという認識です。
運用を開始してから半年ほど経過しましたが、社内システムのサービスに影響がでるような障害は一度も発生していません。
ネットワークパーティション
前回のブログ記事の最後に次のような事を書きました。
VPNの可用性
MySQL 8.0のグループレプリケーションのメンバーステータスの監視を行っていて、メンバーステータスがUNREACHABLEになるアラートが時々発生しています。通常は数分経つと自動的に復帰します(自動復帰する設定を入れています)。ネットワークが復帰してもステータスが復帰しないこともありますが、その話は別の機会に。
メンバーステータスがUNREACHABLEになる原因を調べると、VPNルーター間の経路上でネットワーク断が発生していることがあります。VPNルーターのネットワーク周りで問題が発生していることもありますし、ゾーンのネットワークで問題が発生していることもあります。
マルチクラウド構成のソフトウェアによる拠点間VPNは、このような数分間のネットワーク断が毎月数回発生することを許容して運用する必要があります。
ネットワークパーティションに伴うエラーやメンバーノードの切り離しは時々発生していますが、後述するケースを除き自動復帰できています。
ステータスの不一致
ステータスが復帰しないケースがありました。試験運用時にも発生しており、本運用を開始してからも2回発生しています。
試験運用時に発生したため、先のグループメンバーのステータス監視の機能を開発したのです。
ノードazure-db02において、次のようなステータスになっているとします。
mysql> SELECT MEMBER_HOST,MEMBER_STATE FROM performance_schema.replication_group_members;
+-------------+--------------+
| MEMBER_HOST | MEMBER_STATE |
+-------------+--------------+
| azure-db01 | ONLINE |
| azure-db02 | ONLINE |
| aws-db01 | ONLINE |
| aws-db02 | UNREACHABLE |
| gcp-db01 | ONLINE |
+-------------+--------------+
5 rows in set (0.00 sec)ノードaws-db02に疎通が取れない状況と認識できますが、実際には疎通ができていることがありました。
このとき、ノードaws-db02上でステータスを確認すると次のようにすべてONLINEになっています。自ノード(aws-db02)のステータスがERRORになっていればノードazure-db02でのステータスと整合性があるのですが、実際はONLINEになっています。
mysql> SELECT MEMBER_HOST,MEMBER_STATE FROM performance_schema.replication_group_members;
+-------------+--------------+
| MEMBER_HOST | MEMBER_STATE |
+-------------+--------------+
| azure-db01 | ONLINE |
| azure-db02 | ONLINE |
| aws-db01 | ONLINE |
| aws-db02 | ONLINE |
| gcp-db01 | ONLINE |
+-------------+--------------+
5 rows in set (0.00 sec)ネットワークの一時的な障害を起因として、ステータスがUNREACHABLEになりましたが、ネットワークの障害復旧後にもこのステータスのままになっているようでした。
対応としては、双方のノードで何らかの異常が発生している可能性があるとして、両方ともグループレプリケーションの停止と再開で復旧させました。
メモリリーク
ネットワークパーティションが発生して復旧した後にメモリリークと考えられる事象が発生しました。
5ノード中の2つのノードにおいて、mysqldのメモリ使用量が増加し続けていました。
空きメモリ容量減少のアラートが発生して気がついて、対応としてmysqldの再起動を行いました。その後は再発していません。
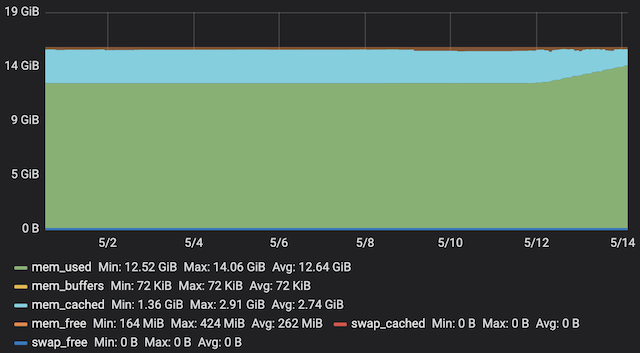
グループレプリケーションのステータス監視によるエラー検知が頻発していたときだったので、グループレプリケーションが何か関係していると思われますが、確実な原因はわかっていません。
ネットワークパーティション自体は時々発生しているので、このときだけなぜこうなったのかもわかりません。
まとめ
- マルチクラウド構成(Azure, AWS, GCP)において、MySQLサーバーの冗長化としてMySQL Group Replicationを利用している。
- マルチプライマリーモード(multi-primary mode)で運用しており、アプリケーションからは同じ拠点内のMySQLサーバーをActive/Passive構成として利用している。
- MySQL用の監視プラグインに対して、MySQL Group Replicationのステータス監視の機能を開発して追加した。
参考サイト
- [Chapter 18 Group Replication
Table of Contents](https://dev.mysql.com/doc/refman/8.0/en/group-replication.html) (MySQL)
- 18.9.2 Group Replication Limitations (MySQL)
- Category Archives: Group Replication (MySQL High Availability)
- HAProxy (HAProxy)
- The Design Philosophy of the DARPA Internet Protocols (ACM SIGCOMM Computer Communication Review Paper Retrieval)
- ttkzw/go-check-plugins/check-mysql (GitHub)