はじめまして。MSPグループの夜勤チームのいかろちゃんです。
夜勤チームには特有の仕事がいくつかあります。
その中のひとつが各サーバにおける監視状況や通知設定が適切な状態にあるかをチェックするという仕事です。
今回はそれについて特にどういう部分を自動化していて、どうやって運用しているのかを紹介します。
はじめに
サーバ監視業務を行ううえで不要なアラートを抑制することは重要です。アラートを抑制しないと大量のアラートに埋もれてしまったり、あるいはアラート通知が「どうせ対応不要のアラートだからいいや」など本当に重要なアラートを見逃してしまう可能性が上がってしまうためです。不要なアラートとして比較的多く見られるものは計画したメンテナンスや作業によるアラートが挙げられます。
ハートビーツ作業やお客様によるメンテナンスの際に一時的に監視通知の停止(以下、通知停止)や監視チェック実行の停止(以下、監視停止)を行うことがあります。このようにして通知を停止した際は、本来は作業終了後に通知を再開しますが、人間が作業する以上、どんなに気をつけても再開を忘れるということが発生してしまいます。そのため該当アラートが通知(or監視)停止のまま長期間放置されるのを防ぐ必要があります。
ハートビーツ内には定期的に監視システムであるNagiosの監視や通知の状態が意図した状態かをチェックする仕組みが存在します。それが「Nagios Check Time」です。以下ではどのようにNagios Check Timeが実装され、運用されているのかを紹介します。
ハートビーツの監視システムについて
Nagios Check Timeを説明する前に、まずはハートビーツの監視システムについて簡単に紹介します。ハートビーツでは監視システムとしてNagiosを利用しています。NagiosはPull型の監視システムです。Nagiosサーバより監視対象に周期的に問い合わせて監視対象ステー タスを取得し、アラート状態であれば通知します。また、さきほど紹介したように通知停止や監視停止など一時的にNagiosの監視・通知等の動作を変更可能です。以下に監視対象ステータスおよび、Nagiosで設定可能である一時的な動作変更について説明します。
監視対象ステータスはOK状態(OK, UP)とアラート状態(WARNING, CRITICAL,UNKOWN, DOWN)が存在します。監視対象ステータスがOK状態からアラート状態へ変化するとアラートの通知が行われます。逆に監視対象ステータスがアラート状態からOK状態へ変化するとリカバリの通知が行われます。またアラート状態でもWARNINGからCRITICALなどの異なる監視対象ステータスへの変化でもアラートが発報します。
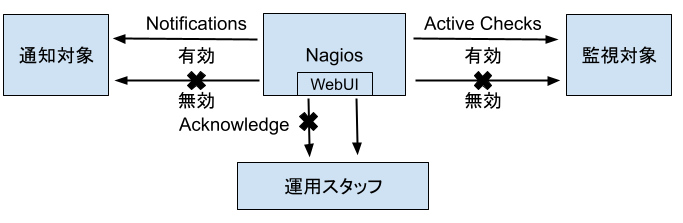
Nagiosで設定可能である一時的な動作変更には監視チェック実行の有効・無効(Active Checks)、通知の有効・無効(Notifications)、確認済み状態(Acknowledge)の3つがあります(以下総称してActive Checks・Notifications・Acknowledge状態)。通知の無効状態は監視対象ステータスの取得は行うものの、監視対象ステータスが変化した場合も通知しない状態です。監視チェック実行の無効状態は監視対象ステータスの取得をしない状態です。したがって監視チェックの無効状態では監視対象ステータスは変化せず通知も行われません。
そしてAcknowledgeがあります。ハートビーツでは運用スタッフはメールの他にNagiosのWebUIでも常時アラート状況を確認しています。そのため、状況を把握しているアラートではWebUI上からの表示をなくしたいことがしばしばあります。そういったときに利用する機能がAcknowledgeです。AcknowledgeはNagiosのWebUI上から表示されなくなるのみで、監視は実行され監視対象ステータスが変化した場合には通知が行われます。
以上のActive Checks・Notifications・Acknowledge状態についてまとめると図のようになります。バツマークのついている矢印がその動作が行われないこと、ついていない矢印は行われることを示しています。
実装
このセクションではNagiosの動作をふまえ、Nagios Check Timeの概念と実装について紹介します。
ハートビーツでは100,000以上の監視対象項目が存在する(2023年07月現在)ため、すべての監視のActive Checks・Notifications・Acknowledge状態をチェックするのは現実的ではありません。そこで1日1回前日との差分をとることによってActive Checks・Notifications・Acknowledge状態が変化した項目を確認します。また、同時に監視サーバ間の差分を確認します(理由は後述)。これらの差分の量は現実的に人間が処理できるサイズに収まります。
Nagiosは定期的にstatus.datというファイルに現在のActive Checks・Notifications・Acknowledge状態を書き出します。Nagiosのstatus.datをパースして定期的にAcknowledge、Notifications、Active Checksの状態を使いやすい形で保存するようにしています。定時になると当日と前日との差分をとります。また、ハートビーツの監視サーバは冗長化されており2台が稼働(+待機系2台)しています。基本的には2台の監視サーバ共にActive Checks・Notifications・Acknowledge状態を揃えます。しかし、場合によってはActive Checks・Notifications・Acknowledge状態を監視サーバによって変えることがあります。そのため、日ごとのActive Checks・Notifications・Acknowledge状態差分だけではなく監視サーバ間のActive Checks・Notifications・Acknowledge状態の違いも把握する必要があります。
そのため、基準となる監視サーバから他方の監視サーバのActive Checks・Notifications・Acknowledge状態を取得しその差分をとります。以上の差分をメールによって毎日定時(05:15)に通知します。
運用
次にどのようにNagios Check Timeを運用しているのかについて説明します。
意図した通知停止・開始や監視停止・開始をした場合はSlackの特定のチャンネルに投稿します。これは経緯を一箇所に集約させ追いやすくすることを目的としておこなっています。Nagios Check Timeのメールが届くと、基本的に夜勤シフトの運用スタッフが対応します。
差分情報を見てSlackの投稿と照らし合わせながら経緯を確認します。しかし、場合によっては社内で利用しているプロジェクト管理ソフトウェア(Redmine)やお客様とのやり取りなどを確認して意図したものかを確認することもあります。明らかな再開忘れがあった場合は通知や監視を再開します。どうしても経緯不明な差分があった場合は日中帯に関連するチームへ確認します。最終的にエビデンスとして経緯を確認したもの(SlackのURL、Redmineのチケット番号など)を載せてメールとして返信します。
まとめ
以上でどのようにNagios Check Timeがどのような方針で実装され、そして運用されているかを紹介しました。どうしても人間がチェックしないといけないところ以外が自動化されており、また人力の部分も集約化されていることにより日にもよりますが慣れた人だと15分 かからずに終わらせることができています。
本記事で紹介したNagios Check Timeの他にも自動化できる部分は自動化をし、必要があれば内製そして仕組み化する文化がハートビーツにはあります。この記事をみて興味を持っていただいた方は採用エントリーをお待ちしております。