はじめまして、2022年4月に入社した技術開発室の基盤システム担当チーム所属の小倉です。以前に滝澤がブログで紹介したメールプロトコル勉強会に参加した新人の1人です。
最近メールストアをマルチクラウド基盤上にクラスタシステムとして構築しました。このシステムではDRBDとPacemakerを用いております。そこで今回は様々な試行錯誤を経て行ったDRBD ClientやPacemaker/Corosyncの設定などについて紹介していきます。
なお、弊社で構築・運用しているマルチクラウド基盤については、WireGuardによるマルチクラウド構成VPNの事例紹介も参照ください。
DRBD Clientとは
DRBDは分散型ブロックデバイスを構築できるソフトウェアです。DRBD Clientはバージョン9.0.13以降から使える機能で、実ディスクを持たずにクラスタへ参加してそのクラスタのストレージを利用できる機能のことです。以降、DRBD Clientの機能を使ったノードのことをDRBDクライアントと呼びます。
DRBDクライアントはディスクレス(※1)ステータスでクラスタに参加します。DRBD Clientを使うことでアプリケーション用サーバからストレージ部分を分離でき、DRBDクライアントはDRBDにより提供されるブロックストレージをネットワーク経由で利用できます。詳細は公式のThe Client ModeやDRBD Clientを参照ください。
また、DRBD9より前では3台以上でクラスタを組む場合はスタッキング(※2)する必要がありましたが、DRBD9では1つのクラスタに32ノードまで参加できます。
※1)本来ディスクレスは異常を示すステータスですが、DRBD Clientを利用しているときは正常なステータスとして扱われます。
※2)レプリケーションした2台のうちの片方と別のもう1台のサーバをレプリケーションさせて3台以上のノードで同期することを指します。(参考:Three-way Replication Using Stacking)
構成の紹介
本記事内では、アプリケーションを動かすDRBDクライアントのサーバを「APサーバ」、DRBD用のディスクを持つサーバを「ストレージサーバ」と呼ぶこととします。
APサーバとストレージサーバの1セットずつ、Azure、AWS、GCPに構築しています。そのうち1台のAPサーバは調停用です。
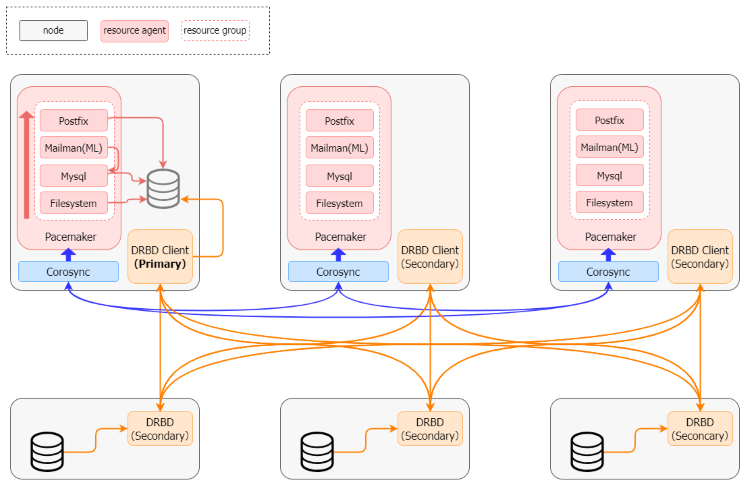
DRBDのストレージには、主にメールボックスとメーリングリスト用データベースを保存しています。
設定の紹介
DRBD、Pacemaker、Corosyncの設定例を紹介します。
DRBDの設定
DRBDの設定例をセクションごとに紹介します。各セクションは入れ子になっており、同じセクションでもどこに定義するかにより適用範囲が変わります。今回は全て1つのresourceセクション内に定義する前提とします。DRBDの設定の詳細はman drbd.conf-9.0を参照ください。
現在のDRBDのパラメータを参照したい場合はdrbdsetup showコマンドを利用します。–show-defaultsオプションを付けるとデフォルトで設定されているパラメータも併せて出力できます。
optionセクション
options {
quorum majority;
on-no-quorum io-error;
}quorum majority;はクォーラムを満たしていると判断する数を過半数とする設定です。クォーラムを満たしているときにプライマリへ昇格できます。ディスクレスのサーバは投票権を持たないためAPサーバは投票権を持ちません。APサーバは2台以上のストレージサーバと接続できている場合にプライマリへ昇格できます。
on-no-quorum io-error;はクォーラムを失ったときのDRBDディスクへのアクセスをIOエラーで返す設定です。
handlersセクション
handlers {
quorum-lost "echo b > /proc/sysrq-trigger";
}quorum-lostにはプライマリサーバがクォーラムを失ったときに実行するコマンドを指定します。スプリットブレインを防ぐためにMagic SysRq keyを利用し即座に再起動します。
netセクション
net {
protocol C;
timeout 200;
connect-int 30;
ping-int 30;
}protocolは同期に利用するプロトコルを指定します。Cは完全同期の設定で全てのノードに書き込みが終わった時点で書き込み完了とします。AとBは非同期でA < B < Cの順でデータ整合性が高くなりますが、レイテンシーとトレードオフの関係となっています。今回は高い整合性が必要で、検証で期待の性能を満たすことを確認したためCを採用しています。
timeout、connect-int、ping-intはそれぞれタイムアウトの調整のために設定しています。timeoutはconnect-intとping-intよりも小さい値にする必要があります。クラウド間でクラスタを組んでいるためデフォルトの値よりも余裕を持たせています。参考までにデフォルトの値と変更後の値を紹介します。検証したところ同じ条件でもばらつきがでたため、あくまで参考値として最大の時間を基に「以内」と表現します。
※「降格までに掛かる時間」は、切断されたノードを対向ノードが切断後に切断したと認識するまでの時間。
volumeセクション
volume 0 {
device minor 0;
disk /dev/disk/by-partlabel/drbd;
meta-disk internal;
}DRBDで作成するボリュームの設定です。これは次のonセクションで定義する各ノードに適用されます。
diskにはデバイス名を指定しますが、デバイス名は起動時の認識する順序や環境によって異なってしまいます。partedコマンドでフォーマットする際にパーティション名を付けると、以下の例のようにシンボリックリンクが作成されてパスを統一できます。なおDRBDクライアントとして動作させる場合にはnoneを指定します。
# parted /dev/sdb1 --script 'mklabel gpt mkpart drbd 0% 100% print quit'
# ls -l /dev/disk/by-partlabel/drbd
lrwxrwxrwx 1 root root 10 Aug 31 18:26 /dev/disk/by-partlabel/drbd -> ../../sdb1meta-disk internal;は内部メタデータを利用する設定です。外部メタデータは既存のディスクにメタデータの領域を確保できないときなどに利用されます。
onセクション
on storage01 { # ノードの名前を指定
address 192.168.1.1:7789; # ノードのIPアドレスとポート番号
node-id 1; # IDを指定
}
~省略~
on app01 { # ノードの名前を指定
address 192.168.2.1:7789;
node-id 4;
volume 0 { # volumeセクションの番号を一致させる
disk none; # DRBD Clientの設定
}
}
~省略~DRBDクラスタに参加するノードの設定をします。node-idとaddressはそれぞれ一意である必要があります。onセクション内でvolumeセクションの設定を上書きしています。
connection-meshセクション
connection-mesh {
hosts storage01 storage02 storage03 app01 app02 app03;
}指定した全てのノードのコネクションをメッシュで構成する設定です。onセクションで定義した名前を指定します。
Pacemaker/Corosyncの設定例
pcsコマンドベースで例を紹介します。一部省略していますが、以下に例を紹介します。
### ① Filesystemリソースエージェント ###
# pcs resource create FS_DRBD ocf:heartbeat:Filesystem device=/dev/drbd0 directory=/opt/drbd fstype=xfs
op monitor OCF_CHECK_LEVEL=20 meta migration-threshold=1
### ② フェンシングの無効化 ###
# pcs property set stonith-enabled=false
### ③ ap03を昇格させない設定 ###
# pcs constraint location group1 avoids ap03=INFINITY
### ④ リソースエージェントのグループ化 ###
# pcs resource group add group1 FS_DRBD MYSQL MAILMAN3 POSTFIX DOVECOT①DRBD9にはオートプロモーションという機能があり、DRBD領域をマウントすると自動でプライマリに昇格しアンマウントするとセカンダリに降格できます。そのためDRBDを直接リソースエージェントで管理する必要はなく、Filesystemリソースエージェントでファイルシステムをマウントするだけで済みます。
OCF_CHECK_LEVEL=20は読み書き両方をチェックする設定、migration-threshold=1は1度でもチェック(monitorアクション)が失敗したらフェイルオーバーする設定です。
②今回は3ノードで運用しクォーラムにてスプリットブレインを回避するためフェンシングは無効化しています。またクラウドを跨いだフェンシングが現実的ではないという理由もあります。
③ap03を調停用ノードとして動作させるため、ap03が昇格しない設定にします。
④今回の構成ではメールサーバやデータベースサーバが起動するには、先にDRBDストレージをマウントしている必要があります。この依存関係を解決するため、リソースエージェントをグループ化し同じノードに定義された順序で起動停止するようにします。ここではMySQL、Mailman3など用のリソースの作成の説明を省略します。
Corosyncのパラメータ調整
Corosyncはクラスタ制御を担っているソフトウェアです。DRBDと同様にクラウド間でクラスタを組むためタイムアウトを調整しています。pcsコマンドでパラメータを無停止で変更できます。設定変更のコマンドの例を以下に示します。
# pcs cluster config update totem token=20000
# pcs cluster config update totem token_retransmits_before_loss_const=10このコマンドをpcsクラスタのノードのいずれかで実行すると、全ノードに設定を反映できます。設定は/etc/corosync/corosync.confにも反映されます。
totem {
version: 2
...{省略}...
token_retransmits_before_loss_const: 10
token: 20000
}
...{省略}...デフォルトの値と変更後の値の表を以下に示します。正常にフェイルオーバーさせるため、DRBDのタイムアウトよりもCorosyncのタイムアウトが長くなるようにします。
以下はCorosyncのデバッグログを有効にして取得したログの抜粋です。1行目は失敗を検知したログです。これは切断後、即座に出力されます。2行目はトークンのタイムアウトとコンセンサスの開始を示すログです。最終行はコンセンサスのタイムアウトのログです。この後フェイルオーバーが開始します。
※見やすいようホスト名などは省略しています。
Feb 01 17:22:28 [KNET ] udp: Received ICMP error from 10.2.92.10: Connection refused 10.2.92.10
Feb 01 17:22:31 [TOTEM ] A processor failed, forming new configuration: token timed out (3650ms), waiting 4380ms for consensus.
Feb 01 17:22:35 [TOTEM ] entering GATHER state from 0(consensus timeout).このようにタイムアウトはおおよそtoken + consensusになることがわかります。なおtoken_retransmits_before_loss_constを変更しても再送回数と再送間隔が変わるだけで全体のタイムアウトの時間は変わりません。
Corosyncが内部で実際に利用しているパラメータは、corosync-cmapctlコマンドで確認できます。上記の表もこのコマンドで取得したものです。これは同じ名前の設定でもcorosync.confの値と異なる場合があるため、注意が必要です。上の表で示した値はcorosync-cmapctlコマンドで確認したものです。タイムアウトに関連するパラメータの関係性と計算式を以下に示します。詳細はman corosync.confを参照ください。
※特に区別したい場合は、corosync.confのパラメータを(conf)、内部で利用されるパラメータを(cmap)と示します。
token(cmap):トークンタイムアウトの時間を定義します。
token(conf) + (ノード数 – 2) × token_coefficient = token(cmap)
consensus(cmap):構成を更新する前にコンセンサスを得るまでのタイムアウトを定義します。tokenよりも大きい値にする必要があります。consensus(conf)に設定しなければ以下の計算式から決定されます。
token(cmap) × 1.2 = consensus(cmap)
token_retransmits_before_loss_const:トークンの再送回数です。
token_retransmit:トークンの再送間隔です。corosync.confでの指定は非推奨で以下の計算式から決定されます。
token(cmap) / (token_retransmits_before_loss_const + 0.2) = token_retransmit
その他の運用にあたっての工夫
その他マルチクラウドで運用するにあたって工夫している点を簡単に紹介します。
監視
旧メールサーバではバーチャルIPアドレスでプロセス監視することでActiveノードのみ監視していました。新メールサーバは各サーバがグローバルIPアドレスを持つようになり従来の監視ができないため、Pacemaker(crm)を介して監視するプラグインを作成しました。また、既存のDRBDの監視プラグインが/proc/drbdから情報を取得するものであり、DRBD9では利用できないためDRBDの監視プラグインも作成しました。
監視プラグインのようにPacemakerとDRBDの情報を別のプログラムで扱いたい場合に、それぞれXMLとJSONで出力できるコマンドがあるため紹介します。
- Pacemaker(XML):crm_mon -r -1 -X
- DRBD(JSON):drbdsetup status –json
リソースエージェント
PacemakerによるフェイルオーバーよりもDRBDの降格の認知が遅れた場合、実際にはプライマリがいないにも関わらず昇格に失敗してしまいます。これを回避するため、簡単ですがプライマリが存在しないことを確認するリソースエージェントを自作しています。Startアクションに以下のような処理をはさむことでFilesystemリソースがマウントを失敗することを防いでいます。なお、タイムアウトの管理はPacemakerの責務としてリソースエージェントでは無限ループにしています。
※参考:https://github.com/linux-ha-japan/doc-ja/blob/master/linux-ha-doc/dev-guides/ra-dev-guide.asc#23-タイムアウト
while true
do
primary_num=$(drbdsetup status r0 |grep Primary -c)
if [ $primary_num == 0 ]; then
break
else
sleep 3
fi
doneリソースエージェントを作成する際は、resource-agentsパッケージに含まれるDummyというリソースエージェントを参考にすると作成しやすいです。
Pacemaker/Corosyncの設定をAnsibleで管理する
pcsコマンドを単純に並べるだけではAnsibleでうまく管理できません。そこで-fオプションを利用するとAnsibleでべき等性を担保して管理できます。-fオプションはファイルに設定を出力するオプションで、最後にそのファイルを基に一括でかつ差分だけを反映できます。
# pcs -f /tmp/tmp_cib.xml resource create FS_DRBD ocf:heartbeat:Filesystem device=/dev/drbd0 directory=/opt/drbd fstype=xfs
~~他にも同じようにコマンドを実行する~~
# pcs cluster cib-push --config /tmp/tmp_cib.xmlさいごに
本ブログでは、メールストアに利用しているDRBDとPacemakerを用いたクラスタシステムの事例を紹介しました。マルチクラウド基盤上ということもあり入念に性能評価や障害試験をし、運用後も継続して改善することで現在では安定して稼働しています。特殊な構成ですが、ひとつの例として参考になれば幸いです。