こんにちは。
エンジニアリンググループ所属の田中です。
皆さんは、日々の運用の中で発生するログについてどのように管理していますでしょうか。
* ログを周期的に圧縮してサーバ内に保存し、かつ一番古いログを削除(ログローテーション)する
* ログを定期的にクラウド内の外部ストレージに転送して管理する(CloudWatchエージェント / Fluentd / etc…..)
など、考えれば考えるほど様々な案が上がります。
今回はログ転送において、私が実際に業務の中でぶつかった問題について紹介します。
本記事の概要としては、下記になります。
* AWS Network Load Balancer + syslogを用いた負荷分散を構成する際には、意図した負荷分散が正しく行えているか確認するべきである。
* 送信元サーバで定期的にAWS Network Load Balancerへ再接続する設定を加えることで、送信先サーバの偏りの緩和や、耐障害性の向上ができる。
今回紹介する事例は下図のような環境で確認、検証しています。
OS: Amazon Linux 2 rsyslogd: 8.24.0
全体的にAWSのプロダクトを用いた記載が多くなってしまうことをご了承ください。
構成
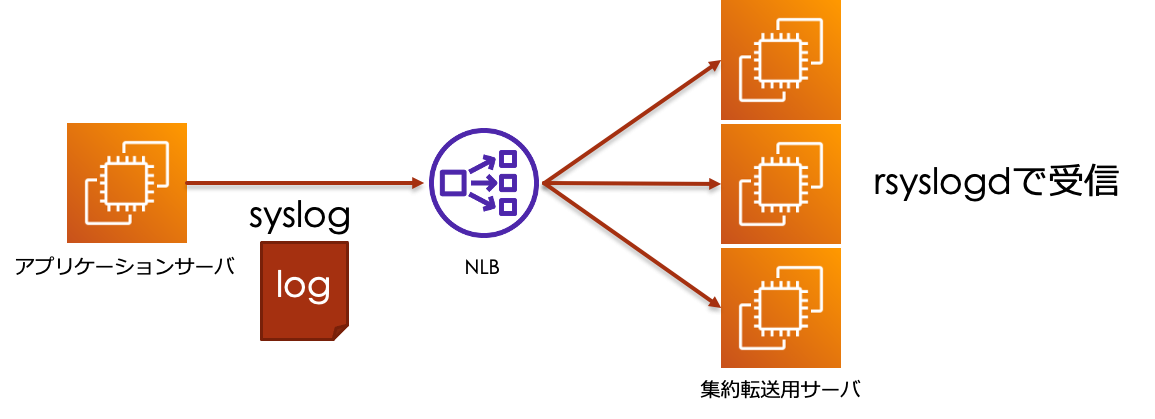
今回紹介する事例では、アプリケーションサーバから常に出力されるログをsyslog(TCP)プロトコルを用いて転送しています。
アクセスの振り分けには、AWS Network Load Balancer(以下、NLB)を用いる構成となっており、
集約転送用サーバ側ではrsyslogdでログを受信する設定をしています。
※図上では簡略化するためアプリケーションサーバが1つになっていますが、実際には複数台存在しています。
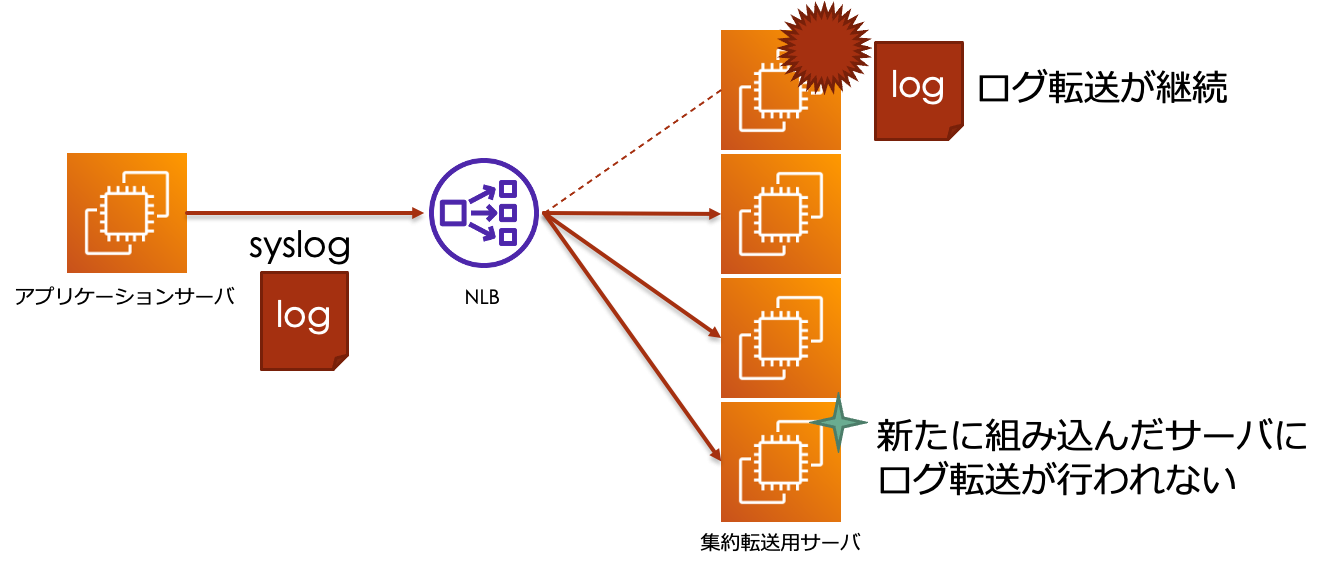
ある日、集約転送⽤サーバの1台にターゲットグループのヘルスチェックに関連しない部分で、障害が発⽣しました。
そこで障害の発⽣している集約転送⽤サーバを手動でターゲットグループから切り離し、別の新しい集約転送⽤サーバを作って組み込むことで復旧を試みました。
しかし、ターゲットグループからの切り離しが完了後もログ転送が停止せず、
また、新たに組み込んだ集約転送⽤サーバに対してログ転送が開始されないという状況に直面しました。
この構成で発生した問題点
発生した問題点としては下記があげられます。
* 問題点1: そもそもとして意図したログの負荷分散が行えていなかった。
* 問題点2: ターゲットグループからの切り離しが行われた後のインスタンスへログ転送が継続されてしまう。
問題点1については、
本来はログがほぼ均一に割り振られるという動作を意図して構成しましたが、
実際は1台のアプリケーションサーバからのログは1台の集約転送⽤サーバにしか振り分けられていない状況でした。
また、各集約転送⽤サーバでログ転送の割り振りに偏りが発⽣してしまっていました。
そのため、構成全体としての負荷分散がうまく行えていませんでした。
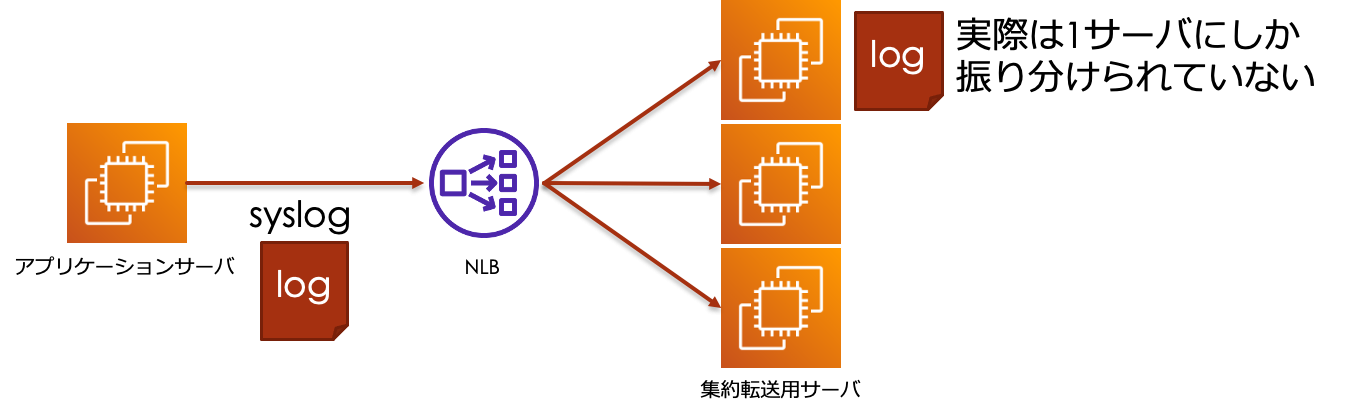
問題点2については、
本来はターゲットグループから切り離したインスタンスに対してはログ転送は行われないことを想定していました。
実際はターゲットグループから切り離し後もログ転送が停止しないことから、障害発生時に新規のインスタンスとの入れ替え対応ができませんでした。
そのため、構成全体としての耐障害性が損なわれていました。
なぜこのようなことが起きたのか
これらの問題についてはsyslogの通信方式と、NLBの動作仕様が絡み合った結果から発生した問題でした。
それぞれの問題点の原因について確認していきましょう。
問題点1「そもそもとして意図したログの負荷分散が行えていなかった」問題については、3つの原因があります。
1つめは、syslogにおける通信の方式にあります。
TCPを利用するsyslogの通信方式は送信の都度、送信先との接続を確立するのではなく、一度確立した接続を保持したまま、転送を続けるよう動作します。
これは実際にNLBのCloudwatchメトリクス、NewFlowCount_TCPが常に増加しないことからも確認できます。
2つめは、NLBの動作の仕組みにあります。
NLBは接続を確立した際、同じ接続を用いるものは接続中、単一のターゲットへルーティングするよう動作します。
そのため接続が切断されない限り、一度送信先が決まると他のインスタンスへの接続が行われません。
この2つの原因によって、1台のアプリケーションサーバからのログは1台の集約転送⽤サーバにしか振り分けられていない状況が発生しています。
3つめは、NLBのアクセスの振り分け方にあります。
NLBは通信における様々な要素(IPアドレス、ポート、プロトコル、etc……)を元にハッシュ値を計算し、
それを元に送信先を振り分けるフローハッシュアルゴリズムによってアクセスを振り分けます。
長期的な目で見ればアクセスは分散すると言えますが、瞬間的な点で見るとタイミング次第で分散の程度には偏りが生じてしまいます。
この偏りによって、一部の送信先への偏りが強くなりすぎた結果、送信先が許容量を超えてしまい、障害につながるといったことも考えられます。
場合によっては、ターゲットグループに組み込んでいるにも関わらず、送信先として割り振られないサーバが発生する可能性もあります。
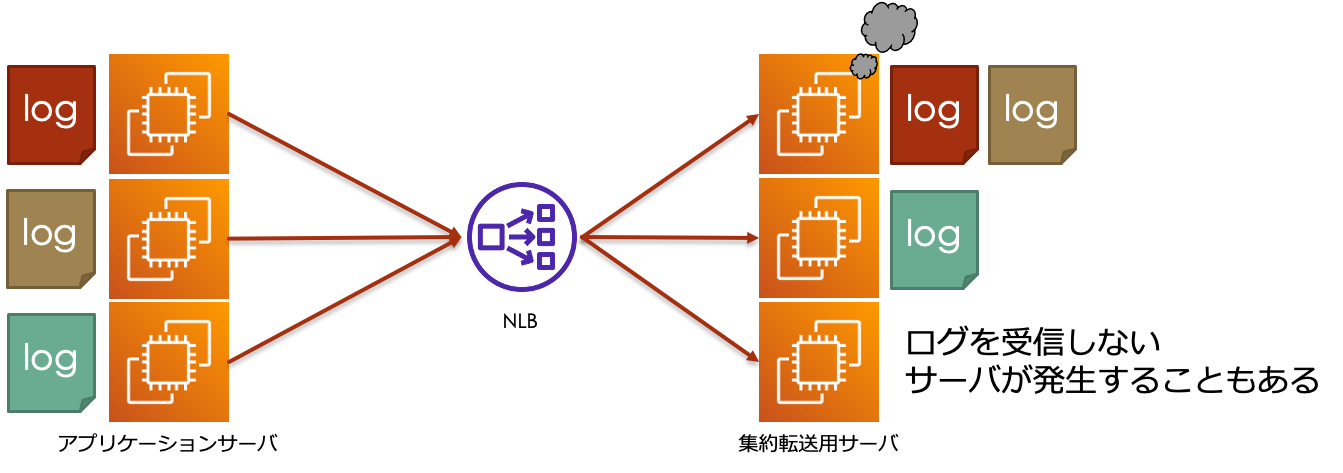
これら3つの原因が問題点1「そもそもとして意図したログの負荷分散が行えていなかった」問題の原因となります。
続いて、問題点2「ターゲットグループからの切り離しが行われた後のインスタンスへログ転送が継続されてしまう」原因については、
AWS公式ドキュメントに下記の通り記載がありました。
登録解除されたターゲットが正常であり、既存の接続がアイドル状態でない場合、ロードバランサーはそのターゲットのトラフィックの送信を継続することができます。
このため、ロードバランサーはすでに確立した接続についてはターゲットグループから切り離したインスタンスに対しても通信を継続してしまいます。
これらが合わさった結果、
* 1台のアプリケーションサーバは1台の集約転送⽤サーバにしかログ転送を行わなず、偏りもあったため、構成全体として意図した負荷分散ができていなかった。
* ターゲットグループから切り離した集約転送⽤サーバでも、すでに接続が確立されて通信が継続しているため、ログ転送が継続してしまっていた。
といった問題を引き起こすこととなりました。
対策
問題点1への対策としては、再度NLBによる接続の振り分けが行われるように、送信元サーバ側から新たに接続をし直すことが必要になります。
rsyslogにはRebindIntervalという設定項目があります。この設定項目では現在の接続が切断され再確立される間隔を指定できます。
この設定を送信元サーバ(前述の構成例ではアプリケーションサーバ)に設定することで設定値分のメッセージを送った後に接続を再確立されるようになります。
仮に10000で設定した場合には、10000メッセージ送信したタイミングで再接続されるようになります。
この設定を加えることでNLBを経由したログ転送先の固定化をある程度緩和できます。
また問題点1への対策は問題点2への対策ともなります。
繰り返し再確立が行なわれるため、ターゲットグループから切り離し後の再接続のタイミングでログの転送先が切り替わるようになります。
発展
先程はrsyslogでの対策を紹介しましたが、送信元で利用しているクライアントがrsyslogとは限りません。
例えばFluetndでsyslog転送する場合等、送信元サーバで利用するクライアントによって実際の設定はその可否から異なります。
そのため、利用しているクライアントで定期的に接続を再確立する設定が可能か確認が必要です。
送信元サーバ側で定期的に接続を再確立する設定ができない場合には、
ターゲットグループの設定として、Connection termination on deregistrationというものがあります。
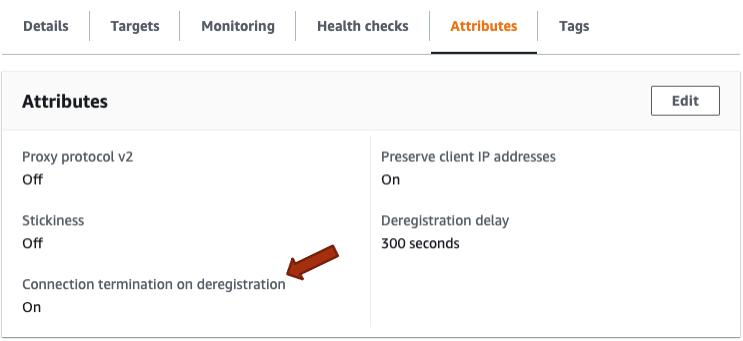
このオプションを有効化することでターゲットグループからのインスタンス切り離し時に確立されている接続を終了させられます。
これにより、送信元サーバ側で定期的に接続を再確立する設定ができない場合でも、問題点2への対策が可能です。
しかし、筆者の検証では切り離し後に他のサーバに転送は継続されるものの、一部ログの欠損が認められたためログの欠損が許されない場合には別途対策を検討する必要があります。
どちらのパターンでも、接続の切断、再確立に伴って実際に送られるべきログが欠損していないかは注意深く観察する必要があります。
運用するシステムごとにログが欠損する可能性をどこまで許容できるかを考えたうえで、適切な対応を選択していきましょう。
終わりに
今回はAWS Network Load Balancer + syslog転送における注意点を紹介しました。
環境構築の際には、意図した負荷分散が正しく行えているかあらためて確認し、より良い運用が行えるようにしていきましょう。
こちらの事例紹介が皆様の何らかの一助になれば幸いです。