こんにちは。技術開発室の與島です。
ハートビーツでは現在、データセンタの物理サーバで稼働している自社システムをマルチクラウドの新基盤に移設するプロジェクトが進んでいます。
先日その一環として、監視システム happoのメトリックサーバをデータセンタの物理サーバからAzureに移設しました。
本エントリでは、その経緯と流れについて紹介します。
監視システム happo
監視システム happoは、ハートビーツにおけるサーバの管理・監視業務に必要な以下のサービスを提供します。
- Nagiosによるチェック監視
- メトリック収集とGrafana + Graphiteによるメトリック可視化
- インベントリ収集とインベントリ情報の保持
今回紹介するメトリックサーバは、2つめの「メトリック収集とGrafana + Graphiteによるメトリック可視化」における、メトリックのデータストアです。時系列データベースのGraphiteを利用しています。
切り替え前のシステム構成と問題点
切り替え前のメトリックサーバは2017年から稼働しているものです。次のような構成でした。
- 物理サーバ
- CentOS 7
- Graphite:
- Graphite-Web 0.10.0_aplha1 (Apache + mod_wsgi)
- Carbon(megacarbonブランチ)
- Ceres
- ファイルシステム(Graphiteデータ領域): Btrfs
物理サーバ1台構成でGraphiteを稼働させています。また、ディスク使用量を節約するためにGraphiteデータ領域のファイルシステムにはBtrfsを利用して、透過圧縮の機能を有効にしています。透過圧縮によって1.5TBのデータが240GBまで圧縮されていました。
問題点1: メトリック書き込みの遅延
サーバが稼働してからしばらくして、Graphiteが受信するメトリックの量に対してディスクへの書き込みが追いつかなくなり、メトリックがグラフに反映されるのが遅れるようになってきました。最近では常に20〜30分程度遅れている状態でした。
現状の要件ではグラフのリアルタイム性が必須というわけではなかったものの、やはり不便な点は多く改善の必要がありました。
Graphiteによるディスクへの書き込みが追いつかない原因は、Graphite自体の書き込みではなくBtrfsのプロセス(btrfs-cleaner, btrfs-transacti)の書き込みによってディスクのパフォーマンスの大半を消費してしまっていることでした。
問題点2: Graphiteのバージョンが古い
2017年頃にサーバが稼働してから、Graphiteのバージョンアップを行っていませんでした。
また、利用しているGraphiteのバージョンが正式にリリースされたものではなかったり、データベースフォーマットのCeresはメンテナンスがアクティブではなくなっていたりと、全体的にGraphiteの最新に追従できていない状態でした。
切り替え後
上記の問題点の対応可否を考慮しつつ、切り替え先のサーバ構成は次のようにしました。
- Azure Virtual Machine
- CentOS 8
- Graphite:
- Graphite-Web 1.1.6 (Nginx + Gunicorn)
- Carbon 1.1.6
- Ceres
- ファイルシステム(メトリック保存領域): XFS
サーバはAzure Virutual Machineで構築します。これはマルチクラウドの新基盤のプライマリサイトがAzureであるためです。OSはCentOS 8を選択しました。
Graphiteは、Graphite-Web・Carbonは2019/11時点の最新である1.1.6にしました。データベースフォーマットのCeresについては、サーバ移設とあわせて既存データのデータベースフォーマットを変更することが困難であると判断し、継続利用することにしました。ただし、バージョンについては2019/11時点のmasterブランチのHEADを利用するようにしています。
Graphiteデータ領域のファイルシステムは、メトリック書き込みの遅延の原因となっていたBtrfsは利用をやめてXFSにしました。
負荷テスト
切り替え前のメトリックサーバでは、メトリック書き込みの遅延という問題がありました。移設にともないこの点を確実に改善する必要があったため、切り替え後のサーバがパフォーマンス的に問題ないことを担保するために負荷テストを実施しました。
負荷テストでは、haggarというツールをForkして少し改造したものを使いました。
- Add
-datapointsoption - fundamental changes of implementation to give loads from a client that spawn as a worker
具体的には、負荷のかけ方を指定するオプションをいくつか追加しているのと、負荷をかけるワーカーの生成方法を変更しています。これは、オリジナルのhaggarでは既存のメトリックサーバのワークロードと同等の負荷を再現するのが難しかったためです。
テストケースは次の3パターンにしました。
- 現状と同程度の量のメトリックを送信
- 現状の1.5倍程度の量のメトリックを送信
- 現状の2倍程度の量のメトリックを送信
負荷テストのメインの目的は「切り替え後のサーバがパフォーマンス的に問題ないことを担保するため」ですので、とりあえずは1だけでもよいのですが、今後どの程度の規模まで許容できるかの参考のために、2、3のケースでも行いました。
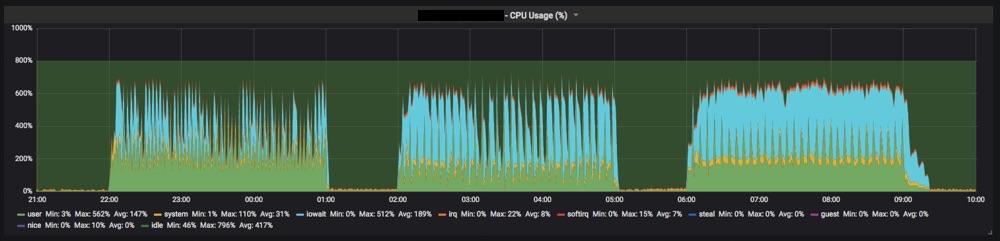
負荷テストの結果から、現状の負荷は問題なく捌けることがわかり、またスペックを上げるのも過剰だろうという判断が出来ました。
なお、ここでの負荷テストの進め方をもとにして、先日個人ブログで以下のエントリを書きました。ツール類や環境は異なりますがリソースグラフのどの値を見るとよいかについては参考になると思います。
参考: Mackerelで負荷テスト中のリソースモニタリングを行う
データ移行
切り替え前の段階でメトリックデータの容量は1.5TB程度ありました。これをダウンタイムをなるべく短くしたうえでどのように移行するかが、今回の移設の最も大きな課題でした。
まず前提となるhappoにおけるメトリックのデータフローについて説明します。
メトリックのデータフロー
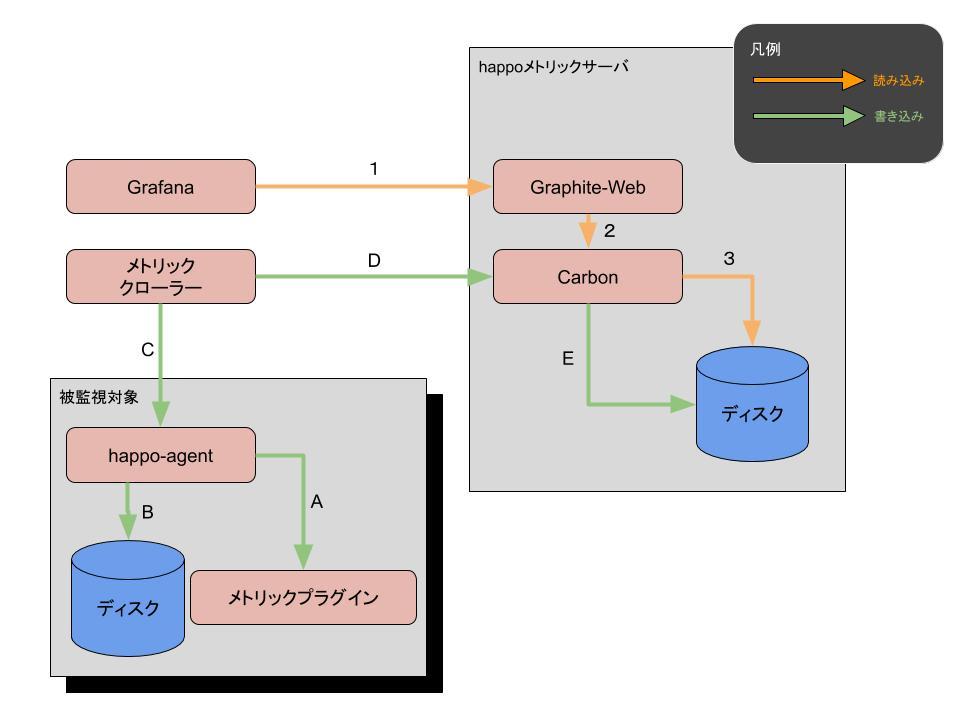
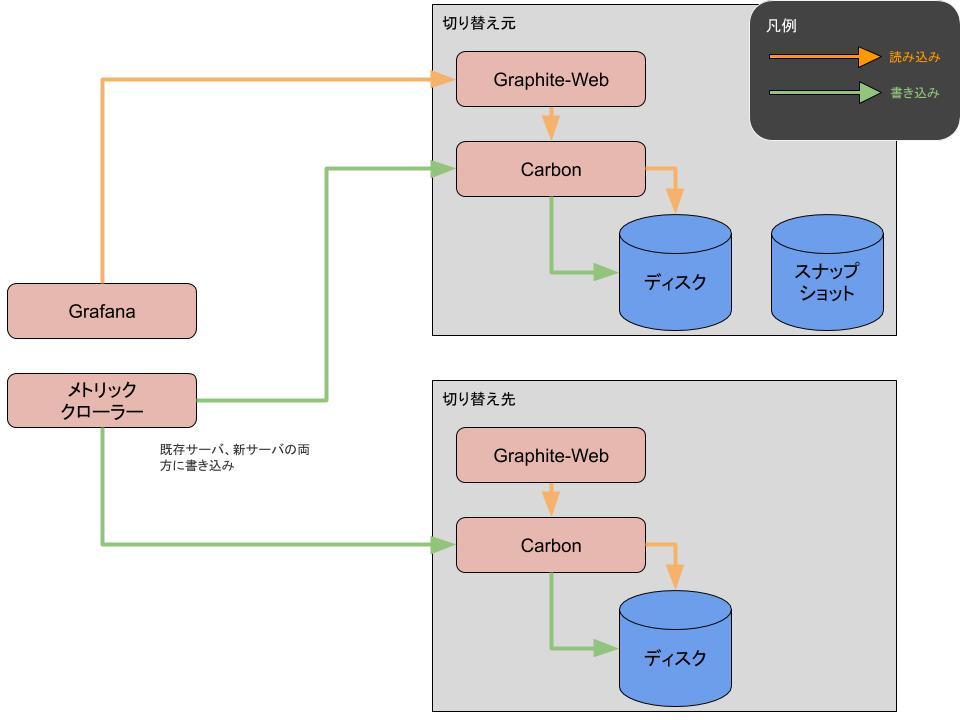
読み込みのデータフローは次のとおりです。
- GrafanaがデータソースとしてGraphite-Webを参照する(1)
- Graphite-WebがCarbonを参照する(2)
- Carbonがディスクからメトリックを読み込む(3)
書き込みのデータフローは次のとおりです。
- happo-agentが1分ごとにメトリックプラグインを実行し(A)、実行結果をローカルに保存する(B)
- メトリッククローラーが数分間隔で起動して各サーバに保存されたメトリックを回収する(C)
- 回収したメトリックをメトリックサーバのCarbonに送信する(D)
- Carbonが受信したメトリックをディスクに書き込む(E)
データ移行方法の検討1
まずはじめに検討したのは次の方法です。
- メトリッククローラーを停止
- メトリックデータを既存サーバから新サーバに転送
- 転送が完了したらメトリック保存先を新サーバに変更したうえでメトリッククローラー再開
シンプルな流れですが、この方法では「2. メトリックデータを既存サーバから新サーバに転送」のあいだは新しいメトリックを書き込むことができず、Grafanaからも参照できなくなるため、転送にかかる時間がそのままダウンタイムになります。
そして、事前検証の際に現状の1.5TB程度のデータを転送するのに1日以上かかるということがわかっており、これはダウンタイムとして許容できない長さであるため別の方法を検討することになりました。
データ移行方法の検討2
次に検討したのは次の方法です。
- メトリッククローラーを停止
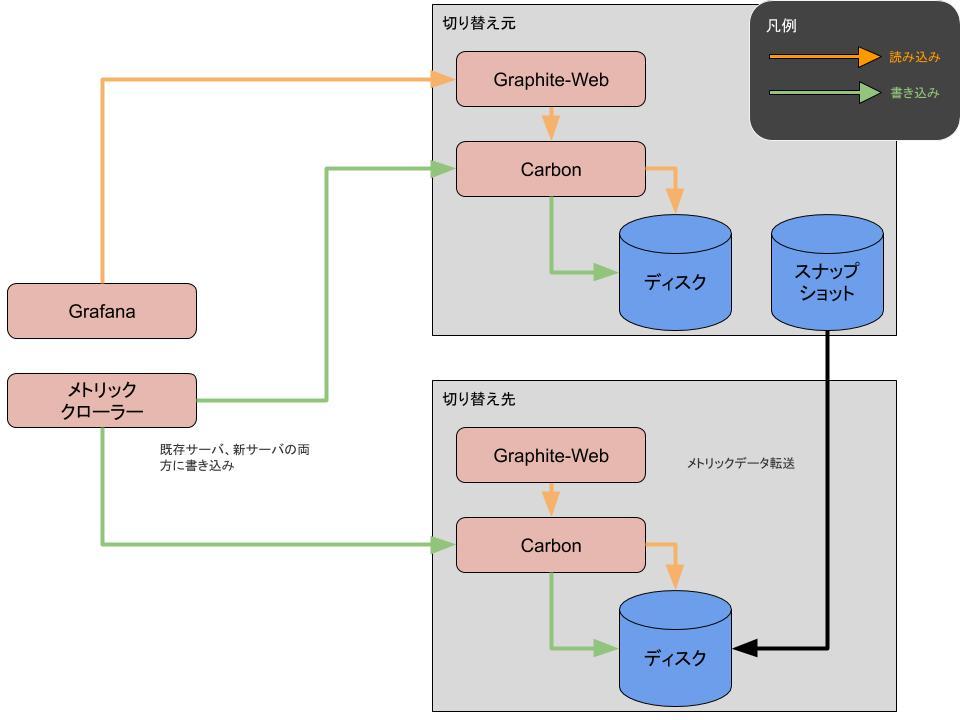
- 既存サーバでGraphite領域のスナップショットを取得
- Btrfsスナップショットを利用
- メトリック保存先を既存サーバ、新サーバの両方にしたうえでメトリッククローラー再開
- メトリック保存先を複数指定する機能の開発を前提
- 2で取得したスナップショットを新サーバに転送
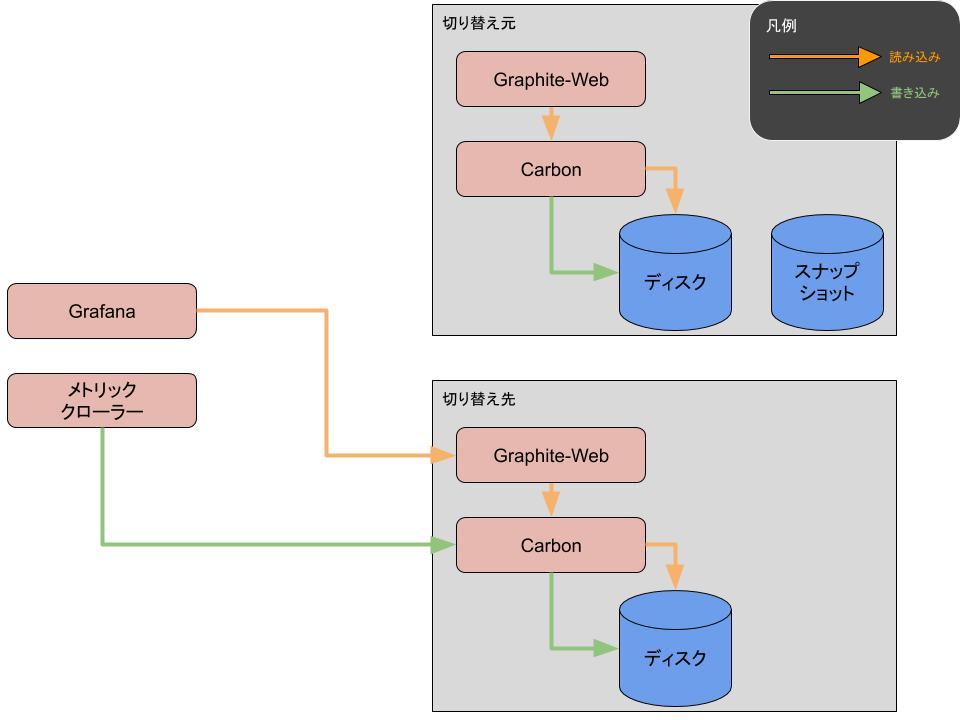
- 4が完了したらメトリック保存先を新サーバに変更
はじめの案と同様に、まずはメトリッククローラーを停止します。次にGraphiteデータ領域のスナップショットを取得することで「1. メトリッククローラーを停止」時点でのメトリックデータができます。
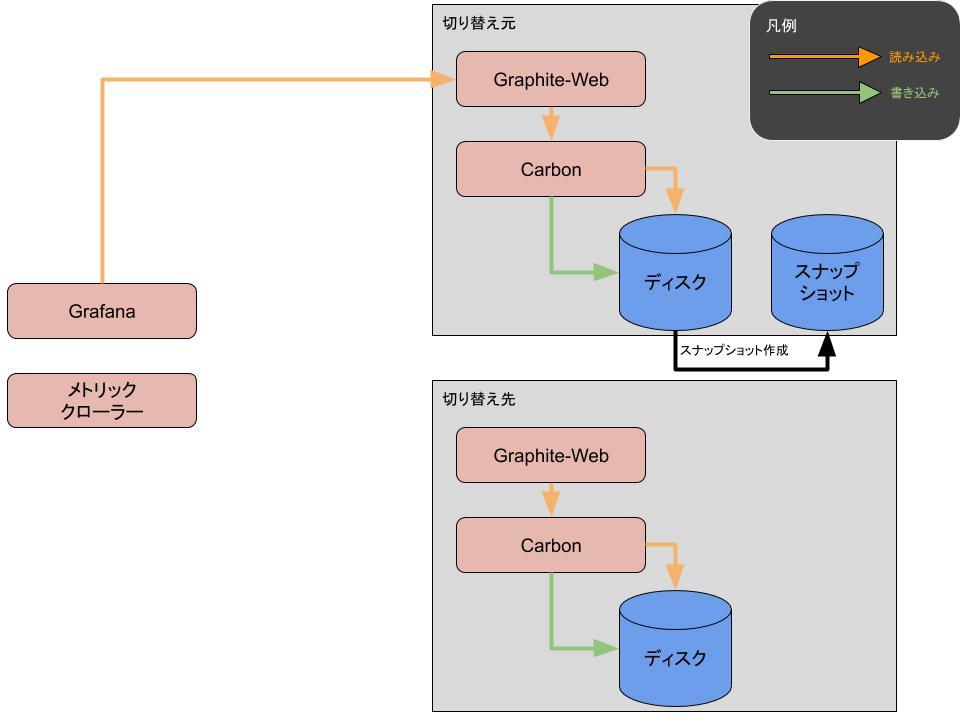
その後メトリッククローラーの保存先を既存サーバ、新サーバの両方とすることで「1. メトリッククローラーを停止」以降のデータが既存サーバ、新サーバの両方に書き込まれることになります。
1と3のあいだがダウンタイムになりますが、Btrfsスナップショットの取得にかかる時間は数秒程度ですので気にするほどにはなりません。
「4. 2で取得したスナップショットを新サーバに転送」では、1.5TB程度のデータを転送することになるので時間がかかりますが、その間もメトリックサーバは稼働しているので、気長に完了を待ちます。
転送が完了したら、その後は既存サーバと新サーバが同じデータを持っていることになるので、あとは任意のタイミングで切り替えればよいだけです。
実際には細かいトラブルは発生しましたが、概ね想定どおりの手順でデータ移行を完了させることができました。
まとめ
新サーバに切り替え後は特に大きな問題点もなく、グラフの遅延も解消されたのでホッとしています。
Graphiteのような時系列データベースを移設した事例はあまり聞いたことがなかったので、この機会に紹介してみました。