こんにちは、滝澤です。
先日、社内ISUCONが開催され、運営側として関わっていました。
その中で、試し解きと技術検証(お遊び)も兼ねて、以前から興味があったメトリック収集と分散トレーシングのフレームワークの OpenCensus を使ってみて、処理時間の可視化をしてみました。
そのときに行った内容などを紹介してみます。
OpenCensusとは
OpenCensusはメトリック収集および分散トレーシングを行うためのライブラリ集です。
マイクロサービスやモノリシックなアプリケーションに対して Observability (可観測性)を提供します。
Google社が社内で利用しているメトリック収集およびトレーシングのライブラリ集であるCensusのオープンソース実装として、2018年1月にリリースされました。
提供する機能としては大きく分けて次のものになります。
サポートしている開発言語としては本記事の執筆時点(2018年9月)では、Java, Go, C++, Erlang, Node.js, Python, PHP, Ruby, C#があります。
開発言語毎にサポート状況は異なるため、詳しくは「FAQ」の「What languages & integrations does OpenCensus support?」を見てください。
OpenCensusはデータを収集するところまでの役割を持っていて、グラフ化したり分析したりするのは他のトレーシング/モニタリングサービスの役割となります。そのため、そのようなサービスへ収集したデータを送信するExporterというものも用意されています。
対応しているサービスとしては本記事の執筆時点(2018年9月)では、Datadog, Instana, Jaeger, Prometheus, SignalFX, Stackdriver, Zipkinがありますが、開発言語や機能毎にサポート状況は異なります。
こちらについても「FAQ」の「What Exporters does OpenCensus support?」を見てください。
なお、OpenCensusの仕様については次のサイトを見るとよいです。
- OpenCensus Specs (GitHub)
Pythonウェブアプリケーションのトレース
ここでは、Pythonウェブアプリケーションでトレーシングを試した例を紹介します。
参考にしたサイトはこちらになります。
- Python (OpenCensus)
- OpenCensus Trace for Python (OpenCensus)
- OpenCensus for Python (GitHub)
環境は以下のものになります。
- 開発言語: Python 3.6
- アプリケーションフレームワーク: Flask
- 分散トレースシステム: Stackdriver Trace (Google Cloud)
なお、Stackdriver TraceはGoogle Cloudの分散トレースサービスです。
用語
作業を始める前に、トレーシングで用いられる用語を確認しましょう。
「Stackdriver Traceの概要」から引用してみます。
– トレース: トレースとは、アプリケーションが受信したリクエストや、リクエストへのレスポンスを生成するために発生したさまざまなイベント(通常は RPC コールまたはインストルメントされたコードのセクション)を正確なタイミングとともに図表として示すものです。こうしたイベントはトレースではスパンとして表されます。
– スパン: トレースのコンポーネント。通常はアプリケーションへの最初のリクエストの結果として実施された RPC コールを表します。
– アノテーション: 特定のスパンに関連付けられたメタデータ。アノテーションの一般的な例としては、スパンが実行されたサービスのバージョン、取得された RPC コールの生成元(トレースのルートスパンの呼び出し元ウェブブラウザのユーザー エージェントなど)に関連するデータ、デベロッパーがスパンに含めるよう選択したカスタムデータなどがあります。
Stackdriver Traceの準備
まず、トレーシングサービスとしてStackdriver Traceを利用するために以下のことを行います。
- Google Cloud Platform(以降、GCPと略す)のプロジェクトを作成する。
- Stackdriver関連のAPIを有効化する。
- Stackdriver Monitoring API
- Stackdriver Trace API
- サービスアカウントを作成し、サービスアカウントキーのファイル(JSON形式)をダウンロードする。割り当てる役割(Role)としては「Cloud Trace Agent」のみを付与する。
- 参考ページ
- サーバー間での本番環境アプリケーションの認証の設定 (Google Cloud)
- 認証の開始 (Google Cloud)
- Webアプリケーション用に次の環境変数を読み込むように設定する。
GOOGLE_CLOUD_PROJECT: GCPのプロジェクトIDGOOGLE_APPLICATION_CREDENTIALS: サービスアカウントキーのファイル名
GOOGLE_CLOUD_PROJECT=tracing-123456
GOOGLE_APPLICATION_CREDENTIALS=/path/to/service-account-file.json
export GOOGLE_CLOUD_PROJECT GOOGLE_APPLICATION_CREDENTIALSなお、Stackdriver Traceを利用するためのチュートリアルが用意されています。
- Setup and Configure Google Stackdriver (OpenCensus)
インストール
次のようにして、OpenCensus Pythonをインストールします。
pip install opencensusさらに、Stackdriver Traceを利用するために、Stackdriver Traceのクライアントライブラリをインストールします。
pip install google-cloud-trace grpc-google-cloud-monitoring-v3以上でOpenCensus Traceを利用する準備が整いました。
使い方
使い方は次のサイトに最低限必要なことは記述されています。
- OpenCensus Trace for Python (OpenCensus)
まず、exporter の用意をします。今回はStackdriver Traceの exporter を用意します。
from opencensus.trace.exporters import stackdriver_exporter
from opencensus.trace.exporters.transports.background_thread import BackgroundThreadTransport
exporter = stackdriver_exporter.StackdriverExporter(
transport=BackgroundThreadTransport
)exporter の送信処理にはデフォルトでは SyncTransport が使われます。これは特別に何かするわけではなく、コード実行中にデータ送信が差し込まれるため、実行処理の遅延が発生します。
コード実行時のブロックを避けるために BackgroundThreadTransport というバックグラウンドスレッドでデータ送信を行う機能が用意されています。上述の例ではこれを利用します。
次に sampler を用意します。
from opencensus.trace.samplers import always_on
sampler = always_on.AlwaysOnSampler()ここでは sampler としてデフォルトの AlwaysOnSampler を指定したので、すべてのデータが送信されます。プロダクション環境での利用でこれを行うと、大量の送信データが発生するため好ましくありません。
そのようなときは、 ProbabilitySampler を使い、送信するデータを減らします。 rate にはサンプリングの比率を指定します。
from opencensus.trace.samplers import probability
sampler = probability.ProbabilitySampler(rate=0.1)exporter と sampler の用意ができたら、 tracer を作成します。
from opencensus.trace import tracer as tracer_module
tracer = tracer_module.Tracer(sampler=sampler, exporter=exporter)以上をまとめると次のようになります。
from opencensus.trace import tracer as tracer_module
from opencensus.trace.samplers import always_on
from opencensus.trace.exporters import stackdriver_exporter
from opencensus.trace.exporters.transports.background_thread import BackgroundThreadTransport
sampler = always_on.AlwaysOnSampler()
exporter = stackdriver_exporter.StackdriverExporter(
transport=BackgroundThreadTransport
)
tracer = tracer_module.Tracer(sampler=sampler, exporter=exporter)これでトレーシングを行う準備が完了しました。
後は、コード中に処理時間を計測したいスパンを設定するだけです。
次のように tracer.span() をwith句で呼び出すことにより、スパンを設定できます。
@app.route('/reset', methods=['GET'])
def reset():
with tracer.span(name='reset'):
with tracer.span(name='delete_data'):
delete_data()
with tracer.span(name='load_data'):
load_data()
with tracer.span(name='prepare_files'):
prepare_files()
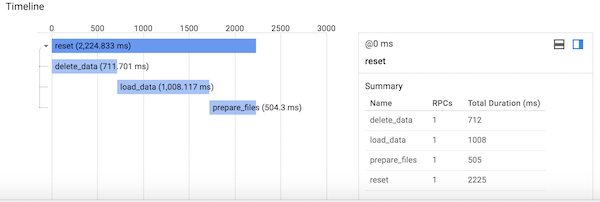
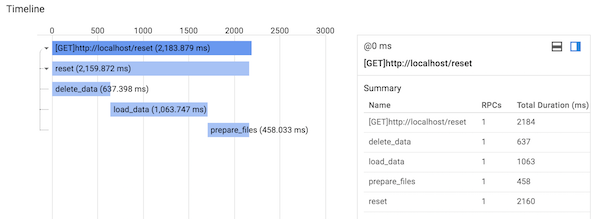
return ('', 204)Stackdriver TraceのTrace listを見ると次のようなタイムラインが取得できます。
また、設定したスパンに対して、add_annotation() によりアノテーションを追加したり、 add_attribute() で属性情報を追加したりすることができます。
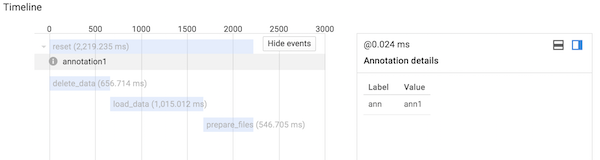
with tracer.span(name='reset') as span:
span.add_annotation('annotation1', ann='ann1')
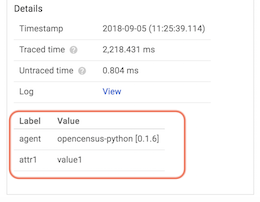
span.add_attribute('attr1', 'value1')このとき、アノテーションは次のように表示されます。
属性情報は次のようになります。
Flaskインテグレーション
OpenCensus Trace for Pythonでは、フレームワークやライブラリに対してインテグレーションが用意されています。
Flaskのインテグレーションも用意されており、次のようにして利用可能です。
from opencensus.trace.ext.flask.flask_middleware import FlaskMiddleware
app = Flask(__name__)
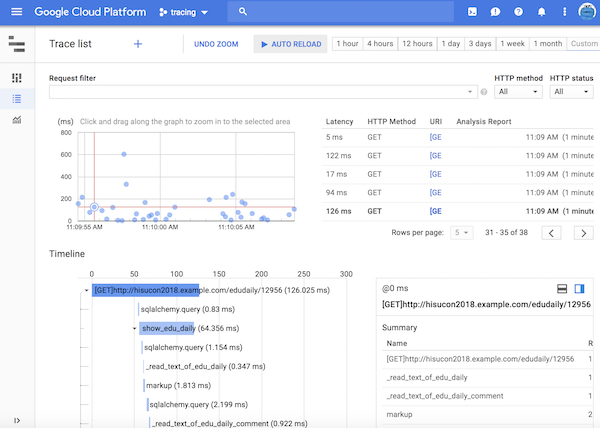
middleware = FlaskMiddleware(app=app, sampler=sampler, exporter=exporter)このときには、次のようなタイムラインが取得できます。HTTPのGETリクエストが加わったことがわかります。
サービスインテグレーション
OpenCensus Trace for Pythonでは、MySQLやPostgreSQLなどのサービスへのアクセスに対してインテグレーションが用意されています。
Object Relational Mapperである SQLAlchemy のインテグレーションを使う場合は次のように記述します。
from opencensus.trace import config_integration
integration = ['sqlalchemy']
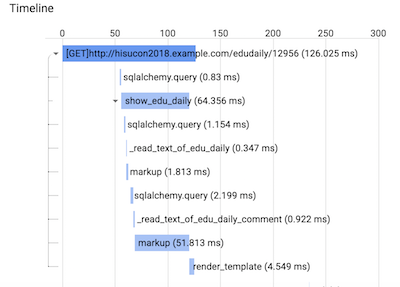
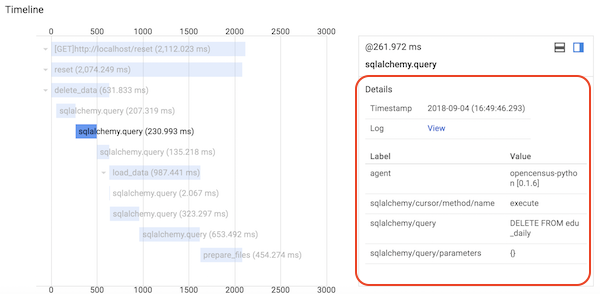
config_integration.trace_integrations(integration, tracer=tracer)このときには、次のようなタイムラインが取得できます。 sqlalchemy.query が加わったことがわかります。

Timelineの sqlalchemy.query をクリックすると、Detailsにクエリーが表示されます。
Noop Tracer
トレーシングを中断したいときには、次のように Tracer を NoopTracer に差し替えると、他のトレーシングに関連する箇所を書き換えなくてもすみます。
from opencensus.trace.tracers import noop_tracer
# tracer = tracer_module.Tracer(sampler=sampler, exporter=exporter)
tracer = noop_tracer.NoopTracer()計測例
計測例を一つ紹介します。
テンプレートエンジンの処理中にデータベースへのクエリーが大量に発生しているのが観測されました。

実はこれはテンプレート中に次のようなSQLAlchemyのO/Rマッパーを利用した記述がループ中にあり、Lazy Loading(遅延読み込み)が発生したためでした。
<p>{{ edudaily.user.name }}</p>コードを書いた人はこのような処理を認識していますが、コードを書いていない人がボトルネックを探すのに役に立ちそうです。
雑感
分散トレーシングはマイクロサービスアーキテクチャでの利用を背景としていますが、モノリシックなウェブアプリケーションでもAPM(Application Performance Monitoring/Management)ツールとして十分に利用価値はあると思います。
複数のミドルウェアや複数のサーバでの処理時間の計測値を集約して可視化することにより、ボトルネックの分析をしやすくなるでしょう。
実際に使ってみた感じでは、スパンの記述が煩雑で、コードの見やすさを阻害しかねないと思いました。
これはライブラリやフレームワークへのインテグレーションを作成して適応することで解決できそうです。
先の例で実際にやったこととしては、処理が重たそうなメソッドに対してラッパーを作成して、ラッパー内でスパンを定義して元のメソッドを置き換えました。
また、インテグレーションで定義されたスパンが関連したスパンとして一つのトレースとして集約されないこともありました。これについては、インテグレーションではスパンの親子関係の記述ができないので難しいと思います。うまく記述する方法があるのかもしれませんがわかりませんでした。
その他
OpenCensusはまだ若いプロジェクトで、開発中であるところが多々ありますが、動向を追っていきたいと思います。
なお、似たようなプロジェクトに OpenTracing というものがあります。こちらも動向を見ていきたいと思っています。
関連しそうなプロジェクトとして、先日、OpenMetrics というプロジェクトがアナウンスされましたが、ブログ記事「OpenMetrics project accepted into CNCF Sandbox」によると、OpenCensusはOpenMetricsをサポートしていくということが述べられています。
こちらもどうなるか様子を見ていきたいですね。
参考サイト
OpenCensus公式サイト
- OpenCensus
- OpenCensus (GitHub)
- OpenCensus Specs (GitHub)
Google Open Source Blog
- OpenCensus: A Stats Collection and Distributed Tracing Framework (Google Open Source Blog)
- How Google uses Census internally (Google Open Source Blog)
- The value of OpenCensus (Google Open Source Blog)
- OpenCensus’s journey ahead: platforms and languages (Google Open Source Blog)
- OpenCensus’s journey ahead: enhanced feature set (Google Open Source Blog)
- OpenMetrics project accepted into CNCF Sandbox (Google Open Source Blog)
OpenCensus Python
- Python (OpenCensus)
- OpenCensus Trace for Python (OpenCensus)
- OpenCensus for Python (GitHub)
Stackdriver Trace
- Stackdriver Trace (Google Cloud)
- サーバー間での本番環境アプリケーションの認証の設定 (Google Cloud)
- 認証の開始 (Google Cloud)