こんにちはCTOの馬場です。
弊社では業種柄、サーバごとのCPU利用率などたくさんの時系列メトリックデータを持っています。
以前はこの収集・閲覧にcactiを利用していましたが、最近はgrafana + graphiteを利用しています。
(ちなみにこれらは全て自社製OSS監視エージェントのhappo経由で収集されます)
今回はこのデータの活用例として弊社で実装している解析・レポーティングについて簡単に紹介します。
できること
全体としては月次レポートを作るしくみです。
- 月次レポートを自動生成
- 月次レポートに、前月の実績値が閾値超過しているグラフを掲載
- 月次レポートに、前月の実績値からの予測値が1ヶ月以内に閾値超過するグラフを掲載
下2つは今回作ったgraphdというアプリケーションで実現しています。
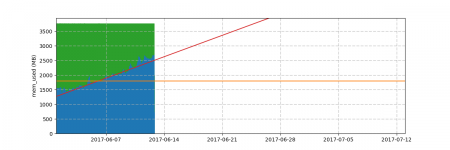
※オレンジが閾値、赤が予測
動作概要
ハートビーツでは HTTPS(HTTP)+JSON を推奨データ通信インターフェースとしていて、graphdもHTTP+JSONでやりとりします。
全体としては
- jenkinsが月次レポート生成ジョブを起動
- 月次レポート生成プログラムがgraphdからデータを取得、その他もろもろを取り揃えてsphinxでレポート生成
という流れです。
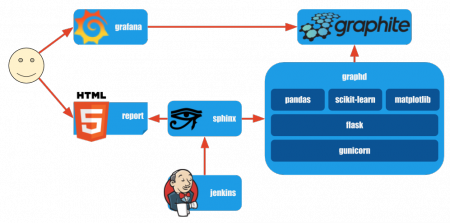
graphdについて詳しくみていくと
- HTTP+JSONで対象システム、閾値、対象期間などを受け取り
- graphiteから対象データを取得
- 予測・閾値超過判定 => 閾値超過するもののみグラフ描画
- HTTP+JSONで対象システム、グラフ(base64)を返却
という流れになっています。
予測はscikit-learnを利用し、前月実績をもとに線形回帰(LinerRegression)しています。
動作環境
前述のとおり月次レポートはsphinxを利用しています。
実は月次レポート生成の仕組みは昔から運用しているものなので、以下はgraphiteと連携したgraphdの部分について話します。
graphdは anaconda3 4.3.1を利用して開発しました。
CentOS6 上の python 3.6, pandas, matplotlib, flask, gunicornで稼働しています。
※サーバなのでXvfbも利用しています
若干苦労したのはmatplotlibまわりです。
matplotlibがマルチスレッド対応していないようなのでマルチプロセスモデルで稼働させています。
またどうにもうまくメモリが開放できずgunicornの --max-requests と --max-requests-jitter にとても小さい値を設定して頻繁に再起動することでしのいでいます。
現状即時性が必要な処理ではないのでこんな形でのんびり運用しています。
分析・グラフ化部分の開発中は、手元でjupyter-notebookを起動して何度もグラフを出力し試行錯誤しました。試行錯誤が楽なのは本当に助かります。
今後について
現状はものすごく素朴なことしかしていないのですが、
今後はたくさんのデータを組み合せた分析や予測もしていければと考えています。
graphd自体は新たな分析パターンを追加しやすいように作ってあるので気軽に機能追加できます。
データをコネコネしていると、それだけで楽しくて、あっという間に日が暮れてしまうので気をつけないと。