こんにちは。斎藤です。
先日のGoogle Compute EngineとGoogle Cloud DNSの解説に続き、今回はGoogle BigQueryを試したいと思います。ビッグデータという言葉がもてはやされる今日、DWHシステムは外せませんよね。
データがそろっていれば、操作は全てWebインタフェースから進められます。そのため、操作のハードルはそれほど高くありませんので、ぜひ試してみて下さい。
前提条件
全ての記述内容は、執筆時点である2014年6月時点の情報を基にしています。今後、変わる可能性があります。
まず、次の条件が揃っている事を確認して下さい。
- 先日のエントリ「Google Cloud Platformをはじめようチュートリアル #gcpja」をお読みになられていて、かつ操作が完了している。
- 簡単なSQLが書ける
次に、今回使うデータについて簡単にご紹介します。
- 内容: サーバから集めたインベントリログの一部 (設定や環境の情報が収まっています)
- レコード数: 約45万件
- 容量: 約900MB
- データフォーマットと例 (CSV) ※実際はヘッダ行はありません
group_name,host_name,command_name,execute_at,command_line,return_code,visible,output,time
"group_name","hostname","command_proc_mounts",1340176929,"cat /proc/mounts",0,1,"rootfs / rootfs rw 0 0
/dev/root / ext3 rw,data=ordered 0 0
/dev /dev tmpfs rw 0 0
/proc /proc proc rw 0 0
/sys /sys sysfs rw 0 0
/proc/bus/usb /proc/bus/usb usbfs rw 0 0
devpts /dev/pts devpts rw 0 0
/dev/sda1 /boot ext3 rw,data=ordered 0 0
tmpfs /dev/shm tmpfs rw 0 0
none /proc/sys/fs/binfmt_misc binfmt_misc rw 0 0
","2012-06-20 07:22:13"JSON形式もサポートしていますが、今回はシンプルにするためにCSVを採用しています。
チュートリアル
BigQuery と Cloud Storage の有効化
BigQueryを使うための手続きを進めます。
Cloud Storageを同時に有効にする理由は、インポートするデータを一時的に保存するにあたってCloud Storageを利用するためです。
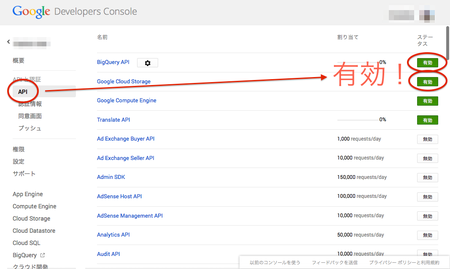
Google Developers Consoleを開き、「APIと認証」→「API」から、BigQuery と Cloud Storageを有効にします。
Cloud Storage への保存
インポートするデータを一時保存するために、Cloud Storageへアップロードします。
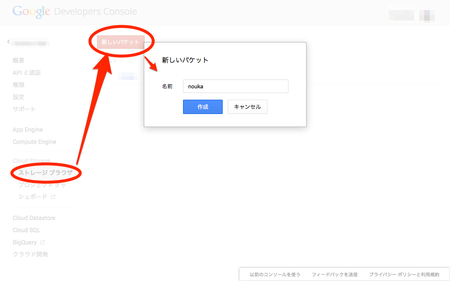
まず、バケットを作成します。例ではnoukaとしました。ご自身で試される場合は別の名前をセットして下さい。
続いて、作成したバケットを開き、用意したCSVファイルをアップロードします。インポートできるデータの詳細は「Loading Data Into BigQuery - Google BigQuery -- Google Developers」を参照して下さい。
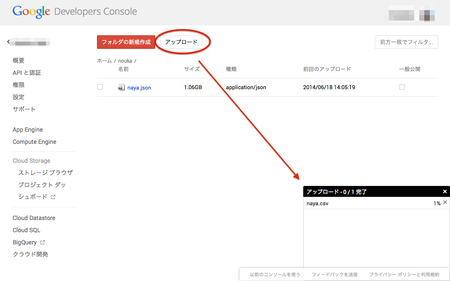
Amazon S3を利用された方なら、とっつきやすいのではと思います。また、アップロードは1GB弱で1〜2時間かかります。お昼休み等にやっておくと良いでしょう。
データのインポート
それでは、データのインポートに入りましょう。
Google Developers Consoleの左側のメニューにある「BigQuery」をクリックすると、次のページが表示されます。早速、以下の図の操作を行ってデータセットを作成してみましょう。名前は"nouka"とします。
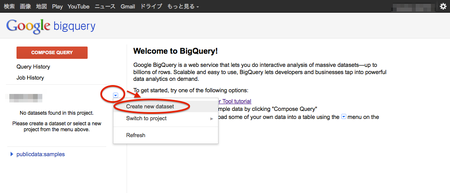
作成したデータセットをマウスオーバーすると「+」ボタンが表示されます。押してみましょう。
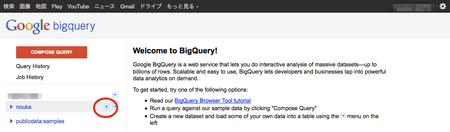
後は、画面の指示に従って情報を入力します。テーブルIDは「naya」にします。
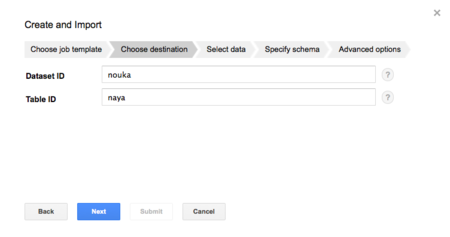
ここで直接アップロードできるファイルサイズは10MBまでです。そのため、事前にCloud Storageにアップロードしました。
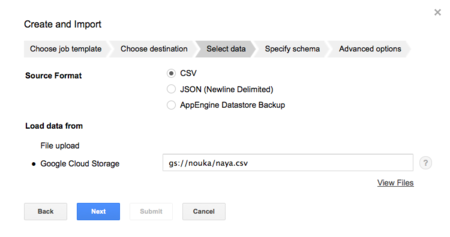
スキーマのフォーマットは、入力画面の「?」マークをクリックすると簡易的な書き方の例が表示されます。CSVであれば、この説明に従えば十分でしょう。なお、今回のデータは次の通りとなります。
group_name:string,host_name:string,command_name:string,execute_at:integer,command_line:string,return_code:integer,visible:boolean,output:string,time:timestamp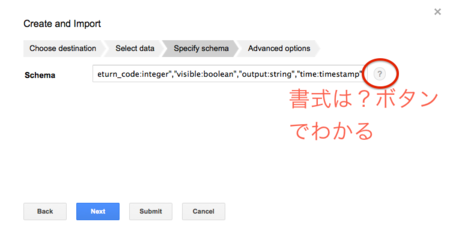
CSVファイルの区切り方について設定します。インポートするデータの書式に沿って設定します。今回は以下の通りです。
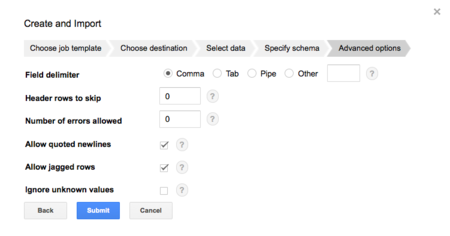
今回のデータ容量ですと、1分程度でインポートが完了します。さすがGoogleさんですね。
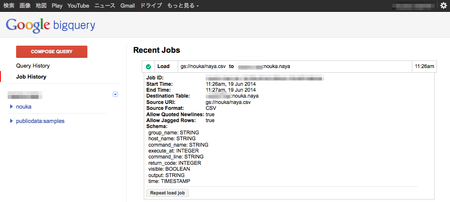
インポートにもし失敗する方がいましたら、フォーマットを確かめてみて下さい。制限の一つに、64KB/レコードがあり、私はこれに引っかかりました。もしはまった方は「Preparing Data for BigQuery - Google BigQuery -- Google Developers」を読んで確認して下さい。
クエリを実行してみよう
準備ができました!それでは、お待ちかねのクエリ実行です。SQLを書かれた事がある方なら、慣れた方法ですからそんなに心配しなくても大丈夫です。詳細は「Query Reference - Google BigQuery -- Google Developers」をご覧ください。
事前に、スキーマの書式を確認します。ご自身がインポート時に設定した内容に沿って出来上がっているでしょうか?よろしければ、「Query Table」をクリックしましょう。SQLを入力するテキストボックスが表示されます。
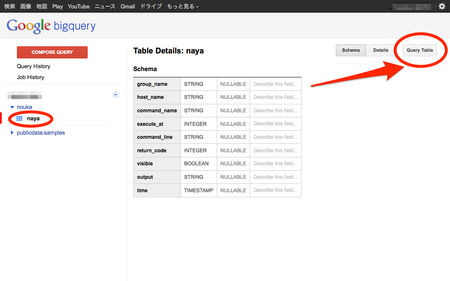
まずは、最後に取得したインベントリデータの日付をデータ種別毎に見てみましょう。
SELECT group_name,
host_name,
command_name,
SEC_TO_TIMESTAMP( MAX( execute_at ) + 32400 ) execute_at
FROM [nouka.naya]
WHERE return_code = 0
AND visible = True
GROUP BY
group_name,
host_name,
command_name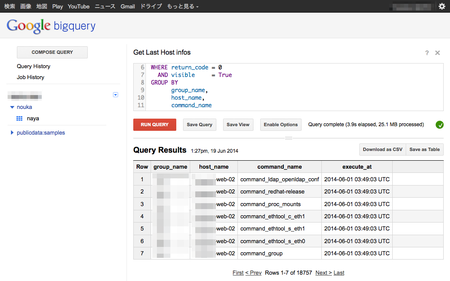
インデックスなどは何も張っていませんが、4秒弱で返されてきました。この速度、Googleの検索システムをお借りしているのだなと感慨深いものがあります。
次は、ちょっと複雑にしまして、各サーバにインストールされている最新のOSがCentOS 6系のホストを探してみます。サブクエリがあり嫌らしいSQLになってしまいましたが、どうでしょうか。
SELECT naya.group_name group_name,
naya.host_name host_name,
naya.output output,
SEC_TO_TIMESTAMP( naya.execute_at + 32400 ) execute_at
FROM [nouka.naya] naya
JOIN ( SELECT group_name,
host_name,
command_name,
MAX( execute_at ) execute_at
FROM [nouka.naya]
WHERE return_code = 0
AND visible = True
GROUP BY
group_name,
host_name,
command_name
) AS last_data
ON naya.group_name = last_data.group_name
AND naya.host_name = last_data.host_name
AND naya.command_name = last_data.command_name
AND naya.execute_at = last_data.execute_at
WHERE naya.command_name = 'command_redhat-release'
AND naya.output LIKE 'CentOS release 6.%'
ORDER BY
naya.group_name,
naya.host_name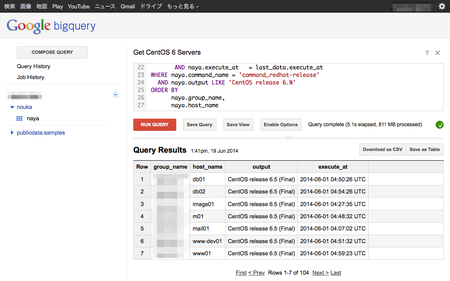
それでも5.1秒で返ってきました。RDBMSだと、適切なインデックスを張った上でスペックを上げないとこの速度は出ないのではと思います。
おわりに
いかがでしたでしょうか。Google BigQueryを利用すると、世界最大級であるGoogleさんが持つ計算機クラスタの力を借りて、今回のチュートリアルならわずか数ドルのコスト(詳細は「Pricing - Google BigQuery -- Google Developers」を参照)で大容量・高速なデータ分析に取り組む事ができます。
これなら、企画担当の方から「ちょっとこのデータ分析してくれない?」と言われても、データさえそろっていれば環境構築の手間はほとんどかけずにデータ分析に勤しむ事ができます。これで、DWH用の大きな機材や高価なソフトウェアを買う手間も省けます。とても便利ですね。
また、運用されているWebサービスから、逐次データを保存する事で最新の情報を分析しやすい環境を構築する事が可能です。詳細は「API Reference - Google BigQuery -- Google Developers」をご覧ください。RESTfulなので、開発しやすそうですね。また、Fluentdとの連携も可能です(例:"fluent-plugin-bigquery")。
それでは皆様、ごきげんよう。