斎藤です。こんにちは。
最近、会社の中で様々な部活動が始まっています。「プログラミング部」や「フットサル部」といったメジャー(?)なものから、「サイクリング部」「P部(プロレス観戦部)」そして「二郎部」などなど、エッジが効いたものまであります。そうそう、私は「サイクリング部」と「P部」に所属しています。
さて、今回はKibanaを使って、Cacti(RRDTool)が収集したモニタリングデータを参照してみようと思います。Cactiはモニタリングデータを収集・ビジュアライズするツールとして普及していますが、他のサーバ・指標と比較するのがちょっと面倒です。そこを、Kibanaを用いてより見やすくしようと言うのが目的です。Kibanaとは、収集したログをGUIで整理しつつビジュアライズできるデータ分析ツールの一種です。たいてい、データストアとしてElasticSearchというNoSQL DBサーバとセットで利用します。
本記事では、「インストール手順」「データインポート」そして「ビジュアライズ」の3点を説明して行きます。なお、既にCactiは動作しているものとします。また、ビルドが行える環境(パッケージグループ"Development Tools")がインストールされている事、またKibanaを稼働させるサーバではhttpd(Apache, nginx等)が稼働している事を前提とします。
※使用した主なソフトウェアは、次の通りです。
- CentOS 6.4 (x86_64)
- Cacti 0.8.8a
- RRDTool 1.4 github版
- Python 2.6.6
- Java SE 1.7.0_45
- ElasticSearch 0.90.7
- Kibana 3.0.0 milestone 4
インストール
はじめに
Cactiが稼働しているサーバを用意してください。また、CentOS 6.4 (x86_64) が入っているサーバを準備してください。なお、Cactiが稼働しているサーバに、ElasticSearch, Kibanaを共存させるか、分けるかは、ご自身の判断で行っていただければと思います。
今回は、CactiとElasticSearch, Kibanaは1つのサーバに共存している前提でお話します。
ElasticSearch, Kibana
まずは、ElasticSearchをインストールします。
Java SE及びElasticSearchのRPMを用意してください。
# yum install jdk-7u45-linux-x64.rpm
# yum install elasticsearch-0.90.7.noarch.rpm
# java -version
(バージョンが正しく表示されればOK)
# chkconfig elasticsearch on
# service elasticsearch start
# ps auxwwf | grep elasticsearch
(プロセスがあがっていればOK)
# curl http://localhost:9200/
(JSONでバージョン等の情報が返ってきたらOK)kibanaは、アーカイブをhttpdのドキュメントルートに展開してインストールします。
# unzip kibana-3.0.0milestone4.zip -d [DocumentRoot]
# cd [DocumentRoot]
# mv kibana-3.0.0milestone4 kibana手元のブラウザから、kibanaのページにアクセスできるかを確認します。
http://[Kibanaをインストールしたサーバのアドレス]/kibana/
無事、図1の通りkibanaのページが表示されれば、OKです。
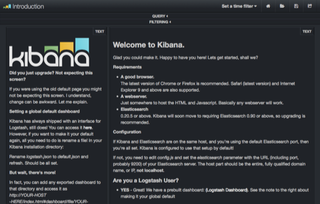 (図1)
(図1)
RRDTool
RRDToolですが、githubにアップロードされている最新の1.x系を利用します。これは、次の段階でインストールするインポートツールがRRDファイルのデータをJSONに変換して取り扱う際に必要となるためです。
# cd /usr/local/src
# git clone git@github.com:oetiker/rrdtool-1.x.git
# cd rrdtool-1.x.git
# ./configure --prefix=/opt/rrdtool-1.4.999
(変なメッセージが出ますがびっくりしない事)
# make
# make install
# cd /opt/rrdtool-1.4.999/bin
# ./rrdtool
(バージョンが表示されればOK)なお、既存のRRDToolは、Cacti用に残しておく事をオススメします。
インポートツール
RRDToolのデータをダンプして、ElasticSearchにインポートするツールをインストールします。今回は、私が取り急ぎ作成したインポートツールを利用したいと思います。このツールは、ElasticSearchが動作するサーバを分けた場合はCactiが動作しているサーバにインストールしてください。
$ cd [cloneを行って良いディレクトリ]
$ git clone git@github.com:koemu/rrd2es.git
$ cd rrd2es
$ pip install -r requirements.txt
$ bin/importElasticSearch.py
("usage bin/importElasticSearch.py YAML_FILENAME"と出ればOK)以上で、データインポートツールのインストールが完了しました。
データインポート
先ほど紹介したインポートツールで、Cactiに登録している全てのホストのデータをElasticSearchに取り込みます。取り込む対象は、Cactiがデフォルトで持っているテンプレートの一部+Percona Monitoring Plugins for Cactiで追加できる項目の一部が対象となっています。日数は10日です。
まず、接続するMySQLおよびElasticSearchのアドレスを設定します。エディタで"conf/import_es.yaml"を開きます。
- db_server_connect: Cactiが利用しているMySQLのサーバ・ユーザ名・パスワードをセット
- es_server: ElasticSearchのサーバのアドレスをセット
その他の設定は、必要に応じて変更してください。
設定が終わりましたら、次のコマンドを実行してインポートを実施します。インポート時、インデックス名としてホスト名を、マッピングタイプ名として"cacti"を利用します。
$ cd [path-to-rrd2es-dir]
$ bin/importElasticSearch.py conf/import_es.yaml最後に、取り込んだデータが正しく取得できるか、確認します。
$ curl http://localhost:9200/[Cactiで取得しているホストのdescription]/cacti/_search?q=hostname:[Cactiで取得しているホストのdescription] | jq ".hits.total"データが正しく入っていれば、0より大きい値が返ります。
注意点として、現時点では重複する区間のデータのインポートした際、どのような挙動を示すかは検証が完了していません。時間をおいて複数期間を取り込む場合は、期間が重複しないようにしてください。
ビジュアライズ
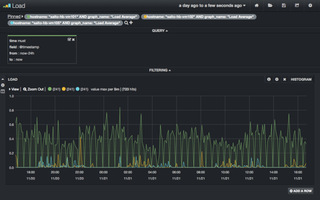
いよいよ、データを比較して行きます。今回の説明では、3台のサーバ"saito-hb-vm[101,102,105]"というホストのLoad Averageを同時にラインチャートとして表示してみます。
手元のブラウザから、Kibanaのページを開きます。
http://[Kibanaをインストールしたサーバのアドレス]/kibana/
続いて、図2のページ下部にあるリンク「Blank Dashboard」をクリックします。
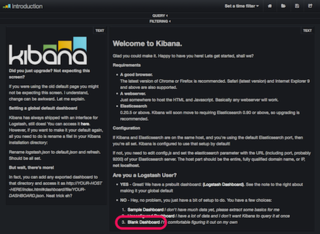 (図2)
(図2)
図3の通り、空っぽの画面が表示されます。ここで、右下にある「ADD A ROW」をクリックします。
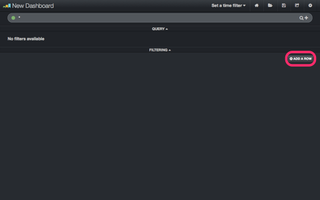 (図3)
(図3)
すると、図4「Dashboard Settings」のページが表示されます。ここでは、パネル(チャート等を挿入する行)の追加などの作業を行います。ここで、上部のタブが「Row」に選択されている事を確認してください。
今回は、「Title:テスト」「Height:300」と入力し、「Create Row」をボタンクリックします。その後、行が1行増えたことを確認し、「Close」ボタンをクリックします。
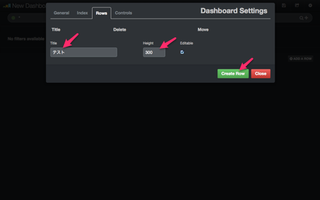 (図4)
(図4)
図5の状態になります。続いて、パネルを追加し、チャートを表示できるようにします。左側の「Add panel to empty row」ボタンをクリックします。
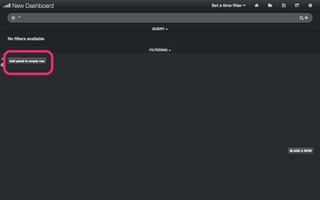 (図5)
(図5)
チャートを登録します。登録内容は図6,7の通りです。設定しましたら「Create Row」をクリックします。
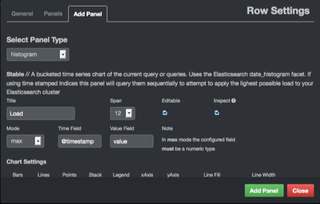 (図6)
(図6) 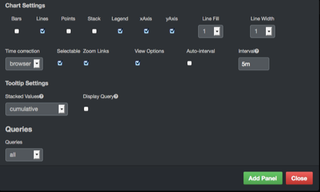 (図7)
(図7)
図8の通り、ラインチャートが表示されました。しかし、どのデータを表示するか絞り込めていない状態です。絞り込んでみましょう。
まずは、ホスト名"saito-hb-vm101"のLoad Averageを参照してみます。上部のQUERY欄の枠に、次の情報を入力しEnterキーを押下します。
hostname: "saito-hb-vm101" AND graph_name: "Load Average"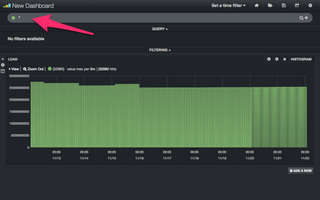 (図8)
(図8)
図9の通り、絞り込まれてLoad Averageが表示されるようになりました。
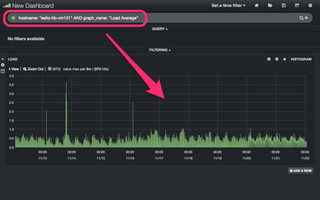 (図9)
(図9)
続いて、表示期間を絞り込みます。右上の「Set a time filter」をクリックし、「Last 24h」をクリックします。結果、図10の通り直近24時間分のデータが表示されるようになりました。
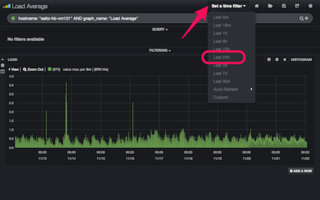 (図10)
(図10)
まずは、1台のホストのデータが表示できるようになりました。ここで、一旦設定を保存してしまいましょう(保存を忘れてブラウザを閉じると作り直しです!)。図11のように、右上のフロッピーボタンをクリックし、名前を付けて保存します。
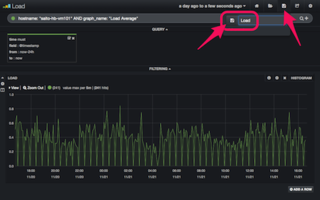 (図11)
(図11)
保存もできた事ですので、残りの2つのサーバのチャートを表示できるように設定してみましょう。
上部のクエリ欄にある検索条件入力枠の右にある「+」ボタンを押すと、検索条件入力枠を増やす事ができます。まずは、枠を1つ増やし、次の検索条件を入力しEnterキーを押します。
hostname: "saito-hb-vm102" AND graph_name: "Load Average"そうすると、図12の通り、チャートが表示されるホストが1つ増えます。
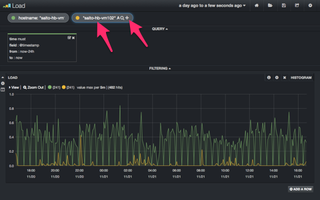 (図12)
(図12)
同様に、"saito-hb-vm105"も増やした状態が図13です。
このようにしますと、例えば複数のWebサーバ同士で負荷の比較をしつつ、著しく高い・低いサーバを見つけたりする事ができます。
(図13)
最後に、設定の保存をお忘れなく。
また、チャートは様々な形態が存在します。Kibana入門 // Speaker Deckというスライドに詳しく解説されていますので、ぜひご覧になりつつ試してみてください。検索条件の記載方法は、Apache Lucene - Query Parser Syntaxを参考にしてください。
なお、ひとつ注意点があります。全く違う指標(例えば、Load AverageとTraffic In)同士で単純に比較しようとすると、スケールがあわず実用的ではありません。その場合は、インポート時に値を正規化してインポートしていただく必要があります。
おわりに
ここまで、Cacti(RRDTool)に保存していたデータをKibanaで表示する方法を、「インストール手順」「データインポート」そして「ビジュアライズ」の3ステップで述べました。WebベースでデータをビジュアライズできるKibanaを使う事で、複数のサーバのモニタリングデータを一つの画面で比較したり、確認できる事がおわかりいただけたかと思います。
同じ事はExcelでもできるかもしれませんし、実際そのようにやられていた方もいらっしゃると思います。ただ、Excelだと大きなデータを扱いづらい場合や、利用に際して感情的に抵抗がある方(?)もいらっしゃったかもしれません。また、KibanaはWebベースですから、Excelに比べたら内容を共有しやすいと思われます。
これを機に、Kibanaを、サービスの利用状況を分析するばかりでなく、ITインフラのモニタリングデータを分析する目的でも、使ってみるのはいかがでしょうか。
それでは皆様、ごきげんよう。
【ハートビーツからのお知らせ】
ハートビーツでは、現在インフラエンジニアを大募集中です!ITインフラを支える「ソフトウェアエンジニア」として、ハートビーツで働いてみませんか?未経験の方でも、しっかりと社内研修を受けた上で取り組む事ができます。詳細は次のページをどうぞ。